




Intel has just announced that its new Data Center GPU Flex Series cards have been added to their family of PluggableDevices, something that is called Intel Extension for TensorFlow.
Intel Extension for TensorFlow is an open-source solution that runs TensorFlow applications on Intel AI hardware, allowing the high-performance deep learning extension for the TensorFlow PluggableDevice interface. It will allow Intel XPU (GPU, CPU, and more) devices to be readily accessible to TensorFlow developers.
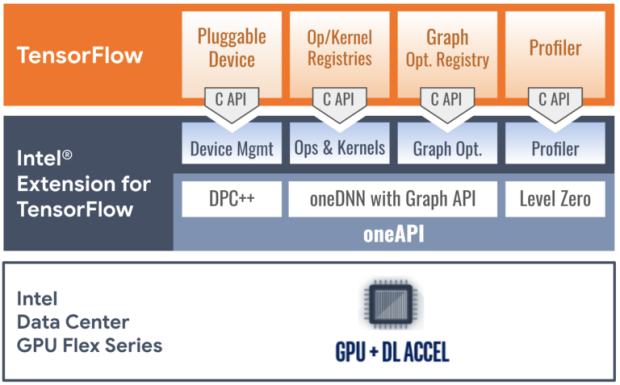
With the new Intel Extension, the company says that developers can train and infer TensorFlow models on Intel AI hardware with "zero code change". Intel Extension for TensorFlow is built on the foundations of the oneAPI software components, with most of the performance-critical graphs and operators being highly optimized by Intel oneAPI Deep Neural Network (oneDNN) which is an open-source, cross-platform performance library for Deep Learning applications.
- Read more: Microsoft previews Shader Model 6.10 with a matrix math API, making neural rendering a standard DirectX feature
- Read more: NVIDIA launches single-slot RTX PRO 4500 Blackwell Server Edition GPU
- Read more: Xbox VP: Project Helix's GPU can generate its own workloads in real time, delivering massive uplift in performance
- Device management: The Intel and Google developers implemented TensorFlow's StreamExecutor C API utilizing C++ with SYCL and some exceptional support provided by the oneAPI SYCL runtime (DPC++ LLVM SYCL project). StreamExecutor C API defines stream, device, context, memory structure, and related functions, all have trivial mappings to corresponding implementations in the SYCL runtime.
- Op and kernel registration: TensorFlow's kernel and op registration C API allows device-specific kernel implementations and custom operations. To ensure sufficient model coverage, the development team matched TensorFlow native GPU device's op coverage, implementing most performance-critical ops by calling highly-optimized deep learning primitives from the oneAPI Deep Neural Network Library (oneDNN). Other ops are implemented with SYCL kernels or the Eigen math library to C++ with SYCL so that it can generate programs to implement device ops.
- Graph optimization: The Flex Series GPU plug-in optimizes TensorFlow graphs in Grappler through Graph C API and offloads performance-critical graph partitions to the oneDNN library through oneDNN Graph API. It receives a protobuf-serialized graph from TensorFlow, deserializes the graph, identifies and replaces appropriate subgraphs with a custom op, and sends the graph back to TensorFlow. When TensorFlow executes the processed graph, the custom ops are mapped to oneDNN's optimized implementation for their associated oneDNN Graph partitions.
- The Profiler C API lets PluggableDevices communicate profiling data in TensorFlow's native profiling format. The Flex Series GPU plug-in takes a serialized XSpace object from TensorFlow, fills the object with runtime data obtained through the oneAPI Level Zero low-level device interface, and returns the object to TensorFlow. Users can display the execution profile of specific ops on The Flex Series GPU with TensorFlow's profiling tools like TensorBoard.
Inside, the Intel Data Center GPU Flex Series 170 is a full-height, single-wide passively cooled card with a 150W TDP. It features a single GPU with 32 Xe Cores, up to 16 TFLOPs of FP32 compute performance, 16GB of GDDR6 memory, and a PCIe 4.0 interface.

Intel also has the Data Center GPU Flex Series 140, a half-height, single-wide passively cooled card with a 75W TDP.
This card has 2 x GPUs with 16 Xe Cores in total (8 x Xe Cores per GPU) which is less than the single-GPU Flex Series 170, with only 8 TFLOPs of FP32 compute performance, and 12GB of GDDR6 memory in total (6GB GDDR6 memory per GPU).
 AMD and Intel Unveil ACE: New matrix instructions deliver a massive 16x AI performance leap over AVX
AMD and Intel Unveil ACE: New matrix instructions deliver a massive 16x AI performance leap over AVX Intel Inside cars, launches 'new' GPU for 'next-level, high-fidelity experiences' in vehicles
Intel Inside cars, launches 'new' GPU for 'next-level, high-fidelity experiences' in vehicles Intel's next-gen Panther Lake CPUs launching at CES 2026, available in Q1 2026
Intel's next-gen Panther Lake CPUs launching at CES 2026, available in Q1 2026 Intel's next-gen 'Crescent Island' data center GPUs: new Xe3P architecture, up to 160GB LPDDR5X
Intel's next-gen 'Crescent Island' data center GPUs: new Xe3P architecture, up to 160GB LPDDR5X Micron intros 9550 Gen5 SSD: the world's fastest data center SSD, 14GB/sec for AI workloads
Micron intros 9550 Gen5 SSD: the world's fastest data center SSD, 14GB/sec for AI workloads This $6 indie is the best-selling game of 2026, beating major AAA releases
This $6 indie is the best-selling game of 2026, beating major AAA releases Halo CE remake's LASO playlist clarified by Halo Studios
Halo CE remake's LASO playlist clarified by Halo Studios Hideo Kojima mourns loss of PlayStation game discs, warns of streaming-only future
Hideo Kojima mourns loss of PlayStation game discs, warns of streaming-only future ASUS ROG Astral RTX 5090 Edition 20 listing appears in Europe for over $7,400
ASUS ROG Astral RTX 5090 Edition 20 listing appears in Europe for over $7,400 NVIDIA RTX 3060 12GB spotted on Newegg for $329, confirming the re-launch
NVIDIA RTX 3060 12GB spotted on Newegg for $329, confirming the re-launch YouTuber shows Vega GPU running FSR 4 with experimental build of OptiScaler and leaked Proton version of FSR 4.1.1
YouTuber shows Vega GPU running FSR 4 with experimental build of OptiScaler and leaked Proton version of FSR 4.1.1 RTX 5090 backplate melts the insulation off a PCIe riser cable in a vertical mount setup
RTX 5090 backplate melts the insulation off a PCIe riser cable in a vertical mount setup Samsung 990 PCIe 4.0 SSD spotted, and it's neither an EVO nor a PRO
Samsung 990 PCIe 4.0 SSD spotted, and it's neither an EVO nor a PRO ThundeRobot claims the ZERO Air 16 is the world's lightest 16-inch RTX 5070 gaming laptop at just 1.64 kg
ThundeRobot claims the ZERO Air 16 is the world's lightest 16-inch RTX 5070 gaming laptop at just 1.64 kg New Steam Machine rival offers a Ryzen 9 CPU and RX 7600 XT for $849, but you have to bring your own RAM
New Steam Machine rival offers a Ryzen 9 CPU and RX 7600 XT for $849, but you have to bring your own RAM The Super Mario Galaxy Movie (2026) 4K Ultra HD Blu-ray Review
The Super Mario Galaxy Movie (2026) 4K Ultra HD Blu-ray Review KTC H49S66 5K2K (5120x1440) 49-inch 180Hz Gaming Monitor Review
KTC H49S66 5K2K (5120x1440) 49-inch 180Hz Gaming Monitor Review HighPoint Rocket 1604L Gen5 x16 NVMe Software RAID AIC Review: half the price with full 59 GB/s speed
HighPoint Rocket 1604L Gen5 x16 NVMe Software RAID AIC Review: half the price with full 59 GB/s speed Next Level Racing ERS3 Haptic Seat Review: immersive sim racing comfort with integrated haptics
Next Level Racing ERS3 Haptic Seat Review: immersive sim racing comfort with integrated haptics ASUS TUF Gaming X870-Pro WiFi7 W NEO Review - Tuffed up
ASUS TUF Gaming X870-Pro WiFi7 W NEO Review - Tuffed up GIGABYTE GO27Q24G Gaming Monitor Review: Glossy OLED Gaming at 240Hz
GIGABYTE GO27Q24G Gaming Monitor Review: Glossy OLED Gaming at 240Hz Lian Li B4-mATX Review: a compact mATX SFF case with excellent airflow and premium features
Lian Li B4-mATX Review: a compact mATX SFF case with excellent airflow and premium features MSI MPG 322UR QD-OLED X24 Review: A Brighter, Tougher 4K 240Hz QD-OLED for $1099
MSI MPG 322UR QD-OLED X24 Review: A Brighter, Tougher 4K 240Hz QD-OLED for $1099 UGREEN NASync DXP4800 GT Review: powerful 4-bay NAS with AMD Ryzen and dual 10GbE ports
UGREEN NASync DXP4800 GT Review: powerful 4-bay NAS with AMD Ryzen and dual 10GbE ports Dell XPS 14 (2026) Laptop Review - Premium Quality, Impressive Performance
Dell XPS 14 (2026) Laptop Review - Premium Quality, Impressive Performance How to Remap Keyboard Keys in Windows using Microsoft PowerToys
How to Remap Keyboard Keys in Windows using Microsoft PowerToys 7 tips to organize your Windows files for faster, easier access
7 tips to organize your Windows files for faster, easier access Intel Arc G3 Extreme first impressions with MSI's Claw 8 EX AI+ - Incredible power for an extreme price
Intel Arc G3 Extreme first impressions with MSI's Claw 8 EX AI+ - Incredible power for an extreme price How to fix Wi-Fi Adapter Not Working on Windows laptops: troubleshooting tips
How to fix Wi-Fi Adapter Not Working on Windows laptops: troubleshooting tips Hisense U7SG 4K TV: Modern Entertainment for the New Age
Hisense U7SG 4K TV: Modern Entertainment for the New Age 6 underrated Microsoft Word features worth using to boost your productivity
6 underrated Microsoft Word features worth using to boost your productivity Level Up Your PC Gaming with these Fantastic ASUS Prime Day Deals on GPUs, Motherboards, and More
Level Up Your PC Gaming with these Fantastic ASUS Prime Day Deals on GPUs, Motherboards, and More GIGABYTE Wants to Kickstart Your New Gaming PC or Upgrade with These Limited-Time Deals
GIGABYTE Wants to Kickstart Your New Gaming PC or Upgrade with These Limited-Time Deals 7 Windows settings to change right after installation for better privacy, security, and performance
7 Windows settings to change right after installation for better privacy, security, and performance I stopped Windows 11 notifications from interrupting me with Do Not Disturb, Focus, and a priority list
I stopped Windows 11 notifications from interrupting me with Do Not Disturb, Focus, and a priority list