



NVIDIA has just announced its new A30 Tensor Core GPU which the company calls its "most versatile mainstream compute GPU for AI inference and mainstream enterprise workloads".

The new NVIDIA A30 Tensor Core GPU was built for AI inference at scale, packing an Ampere GPU with 24GB of HBM2 memory with 933GB/sec of memory bandwidth available. NVIDIA includes third-gen NVLink support here with 200GB/sec of bandwidth available between GPUs in multi-GPU situations.
We have peak FP32 performance of 10.3 TFLOPs, peak FP64 performance of 5.2 TFLOPs and peak FP64 Tensor Core performance of 10.3 TFLOPs -- all within a 165W low-power TDP. Not only that, but the NVIDIA A30 Tensor Core GPU runs on a regular PCIe 4.0 card which will slot into mainstream servers.

We have some huge upgrades over the NVIDIA T4 and NVIDIA V100 cards, with massive uplifts in performance across a multitude of professional situations and applications.
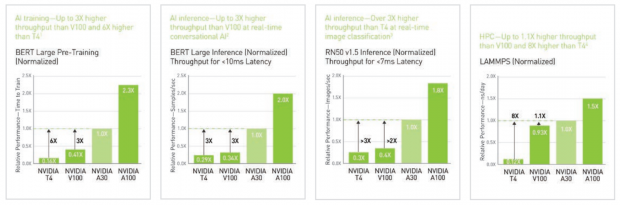
Depending on the software, you're looking at a 6x increase in performance over the NVIDIA T4 with the new NVIDIA A30 in BERT Large Pre-Training (Normalized) and up to an insane 8x increase in performance over the NVIDIA T4 with the new NVIDIA A30 in LAMMPS (Normalized). That's quite the performance gain there, NVIDIA.
The new NVIDIA A30 Tensor Core GPU can be used in multi-instance GPU (MIG) scenarios, which will let developers get access to four GPU instances -- fully isolated at the hardware level with their own HBM2, cache, and compute cores. You could have 4 x MIGs with 6GB HBM2 each, 2 x MIGs with 12GB HBM2 each, or a single MIG with 24GB of HBM2 with the new NVIDIA A30 Tensor Core GPU.

 Thunderobot's new MIX GAMING 2: thin-and-tall, but very slim PC easily runs games at 4K 60FPS+
Thunderobot's new MIX GAMING 2: thin-and-tall, but very slim PC easily runs games at 4K 60FPS+ Razer's new Core X V2 external Thunderbolt 5 GPU enclosure now available, costs $350
Razer's new Core X V2 external Thunderbolt 5 GPU enclosure now available, costs $350 MaxSun's tweaked ARL-HX Micro Station: Intel Core Ultra 9 275HX + dual Arc PRO B60 24GB GPUs
MaxSun's tweaked ARL-HX Micro Station: Intel Core Ultra 9 275HX + dual Arc PRO B60 24GB GPUs Beelink's new GPU dock features built-in 600W PSU: handles monster RTX 4090 as external GPU
Beelink's new GPU dock features built-in 600W PSU: handles monster RTX 4090 as external GPU MaxSun's new Intel Arc Pro B60 Dual 48GB Turbo dual-GPU card has been listed in US for $3000
MaxSun's new Intel Arc Pro B60 Dual 48GB Turbo dual-GPU card has been listed in US for $3000 Nintendo Direct announced for June 9, new Zelda, Mario and more expected
Nintendo Direct announced for June 9, new Zelda, Mario and more expected INNO3D showcases new GeForce RTX GPU designs, with one including Founders Edition-style cooling
INNO3D showcases new GeForce RTX GPU designs, with one including Founders Edition-style cooling Hands-on with MSI's new Claw 8 EX AI+ handheld, Intel Arc G3 Extreme continues to impress
Hands-on with MSI's new Claw 8 EX AI+ handheld, Intel Arc G3 Extreme continues to impress DLSS 4.5 Ray Reconstruction looks fantastic, and it's the missing piece of DLSS 4.5
DLSS 4.5 Ray Reconstruction looks fantastic, and it's the missing piece of DLSS 4.5 Hideo Kojima calls AI a 'janitor for creative chores' after backlash over his appearance in an AI-generated promo
Hideo Kojima calls AI a 'janitor for creative chores' after backlash over his appearance in an AI-generated promo GMKtec EVO-X3 mini PC is coming with OCuLink support and a Ryzen AI MAX+ PRO 495 variant packing 192GB of memory
GMKtec EVO-X3 mini PC is coming with OCuLink support and a Ryzen AI MAX+ PRO 495 variant packing 192GB of memory The new Tomb Raider: Legacy of Atlantis has an AI disclaimer on its Steam page
The new Tomb Raider: Legacy of Atlantis has an AI disclaimer on its Steam page Xbox clarifies exclusive game strategy, confirms multi-platform live services
Xbox clarifies exclusive game strategy, confirms multi-platform live services GIGABYTE claims a DDR5 world record for hitting 13556 MT/s at Computex 2026
GIGABYTE claims a DDR5 world record for hitting 13556 MT/s at Computex 2026 IQUNIX Magi96 Pro Aluminum Low Profile Mechanical Keyboard Review - Premium Build, Satisfying Sound
IQUNIX Magi96 Pro Aluminum Low Profile Mechanical Keyboard Review - Premium Build, Satisfying Sound Asetek Forte S-Series Racing Simulator Bundle Review
Asetek Forte S-Series Racing Simulator Bundle Review Razer Pro Type Ergo Wireless Split Ergonomic Keyboard Review - Built for Comfort and Support
Razer Pro Type Ergo Wireless Split Ergonomic Keyboard Review - Built for Comfort and Support ASUS ROG Strix Morph 96 Wireless Gaming Keyboard Review - Great Performance, More Affordable
ASUS ROG Strix Morph 96 Wireless Gaming Keyboard Review - Great Performance, More Affordable SAPPHIRE Radeon RX 9070 GRE PULSE OC Review - A New 1440p Challenger Has Arrived
SAPPHIRE Radeon RX 9070 GRE PULSE OC Review - A New 1440p Challenger Has Arrived NZXT H6 RGB+ Compact Dual-Chamber Chassis Review
NZXT H6 RGB+ Compact Dual-Chamber Chassis Review ASRock Radeon RX 9070 GRE Steel Legend Review - The RDNA 4 Mid-Range Reshuffle
ASRock Radeon RX 9070 GRE Steel Legend Review - The RDNA 4 Mid-Range Reshuffle ASRock Z890 Taichi Aqua Motherboard Review - Flagship features without the flagship price
ASRock Z890 Taichi Aqua Motherboard Review - Flagship features without the flagship price GIGABYTE Z890I AORUS Ultra Motherboard Review - Mini-ITX with surprisingly good thermals
GIGABYTE Z890I AORUS Ultra Motherboard Review - Mini-ITX with surprisingly good thermals Seagate FireCuda X1070 4TB SSD Review - A New Mainstream Contender
Seagate FireCuda X1070 4TB SSD Review - A New Mainstream Contender The PowerToys utilities I keep enabled on every Windows 11 PC, and the ones I turned off within a week
The PowerToys utilities I keep enabled on every Windows 11 PC, and the ones I turned off within a week TweakTown's Best of Computex 2026 Awards - The Best Hardware, Gaming Gear, and AI
TweakTown's Best of Computex 2026 Awards - The Best Hardware, Gaming Gear, and AI Phison E37T SSD Controller Exclusive Preview - The Fastest DRAMless SSD Platform Yet
Phison E37T SSD Controller Exclusive Preview - The Fastest DRAMless SSD Platform Yet USB Ports Not Working in Windows 11? Try These Fixes
USB Ports Not Working in Windows 11? Try These Fixes ASUS WiFi Routers and Networking Solutions Deliver Long-term Security and Reliability with No Additional Cost
ASUS WiFi Routers and Networking Solutions Deliver Long-term Security and Reliability with No Additional Cost Second Monitor Not Detected in Windows 11? Try These Fixes
Second Monitor Not Detected in Windows 11? Try These Fixes Turn Your Old Smartphone Into a Dedicated Webcam for Your Windows PC
Turn Your Old Smartphone Into a Dedicated Webcam for Your Windows PC The Send To menu is the right-click feature on Windows 11 that nobody bothers to customize
The Send To menu is the right-click feature on Windows 11 that nobody bothers to customize Windows 11 will not let you pin a folder to the taskbar, but a 30-second workaround does
Windows 11 will not let you pin a folder to the taskbar, but a 30-second workaround does ASUS ProArt Displays Unlock Creativity with Professional Monitors for Everyone
ASUS ProArt Displays Unlock Creativity with Professional Monitors for Everyone