



NVIDIA has just announced its new A30 Tensor Core GPU which the company calls its "most versatile mainstream compute GPU for AI inference and mainstream enterprise workloads".

The new NVIDIA A30 Tensor Core GPU was built for AI inference at scale, packing an Ampere GPU with 24GB of HBM2 memory with 933GB/sec of memory bandwidth available. NVIDIA includes third-gen NVLink support here with 200GB/sec of bandwidth available between GPUs in multi-GPU situations.
Popular Now: GTA 6 physical copies in Japan have a 170-day expiration dateWe have peak FP32 performance of 10.3 TFLOPs, peak FP64 performance of 5.2 TFLOPs and peak FP64 Tensor Core performance of 10.3 TFLOPs -- all within a 165W low-power TDP. Not only that, but the NVIDIA A30 Tensor Core GPU runs on a regular PCIe 4.0 card which will slot into mainstream servers.

We have some huge upgrades over the NVIDIA T4 and NVIDIA V100 cards, with massive uplifts in performance across a multitude of professional situations and applications.
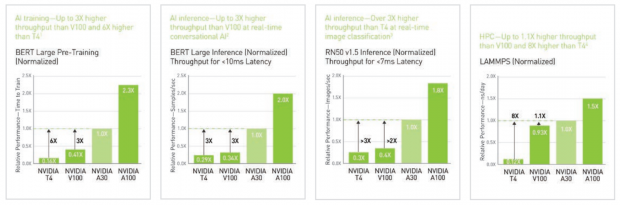
Depending on the software, you're looking at a 6x increase in performance over the NVIDIA T4 with the new NVIDIA A30 in BERT Large Pre-Training (Normalized) and up to an insane 8x increase in performance over the NVIDIA T4 with the new NVIDIA A30 in LAMMPS (Normalized). That's quite the performance gain there, NVIDIA.
The new NVIDIA A30 Tensor Core GPU can be used in multi-instance GPU (MIG) scenarios, which will let developers get access to four GPU instances -- fully isolated at the hardware level with their own HBM2, cache, and compute cores. You could have 4 x MIGs with 6GB HBM2 each, 2 x MIGs with 12GB HBM2 each, or a single MIG with 24GB of HBM2 with the new NVIDIA A30 Tensor Core GPU.

 NVIDIA launches single-slot RTX PRO 4500 Blackwell Server Edition GPU
NVIDIA launches single-slot RTX PRO 4500 Blackwell Server Edition GPU Intel's new Gaudi 3 AI accelerator launched: cheaper than NVIDIA H100 AI GPU, but also slower
Intel's new Gaudi 3 AI accelerator launched: cheaper than NVIDIA H100 AI GPU, but also slower NVIDIA launches cute and tiny RTX 2000E Ada workstation GPU: single-slot, 16GB GDDR6 ECC memory
NVIDIA launches cute and tiny RTX 2000E Ada workstation GPU: single-slot, 16GB GDDR6 ECC memory NVIDIA unveils GB200 NVL4: four Blackwell GPUs, dual Grace GPUs, 1.7TB memory, 5400W of power
NVIDIA unveils GB200 NVL4: four Blackwell GPUs, dual Grace GPUs, 1.7TB memory, 5400W of power Intel and AMD are locking Chinese customers into long-term CPU deals as server chip prices climb more than 40%
Intel and AMD are locking Chinese customers into long-term CPU deals as server chip prices climb more than 40% Ubisoft CEO says Sony's PlayStation disc shutdown will not disturb the industry too much
Ubisoft CEO says Sony's PlayStation disc shutdown will not disturb the industry too much Vibe coding is flooding the App Store with new apps - on track for record submissions in 2026
Vibe coding is flooding the App Store with new apps - on track for record submissions in 2026 Geekbench 7 is out with CUDA support, smarter multi-core scoring, and new AI workloads across all major platforms
Geekbench 7 is out with CUDA support, smarter multi-core scoring, and new AI workloads across all major platforms GTA 6 physical copies in Japan have a 170-day expiration date
GTA 6 physical copies in Japan have a 170-day expiration date Ubisoft believes remakes can be more profitable than new releases, after Black Flag Resynced exceeds expectations
Ubisoft believes remakes can be more profitable than new releases, after Black Flag Resynced exceeds expectations AMD is preparing the 8-core Ryzen 7 9800HX3D CPU for laptops with 96MB L3 cache
AMD is preparing the 8-core Ryzen 7 9800HX3D CPU for laptops with 96MB L3 cache Blizzard fires World of Warcraft game master for abusing god-like powers
Blizzard fires World of Warcraft game master for abusing god-like powers GIGABYTE adds CXMT DDR5 support to AM5 motherboards, supporting speeds up to 8200 MT/s
GIGABYTE adds CXMT DDR5 support to AM5 motherboards, supporting speeds up to 8200 MT/s Xbox 360 tech powers backwards compatibility on PC, original Xbox games use Xefu emulation
Xbox 360 tech powers backwards compatibility on PC, original Xbox games use Xefu emulation Thrustmaster T.Flight HOTAS 5 MSFS Edition Review
Thrustmaster T.Flight HOTAS 5 MSFS Edition Review SteelSeries Arctis Nova Pro Omni Wireless Headset Review - One Headset to Rule Them All
SteelSeries Arctis Nova Pro Omni Wireless Headset Review - One Headset to Rule Them All SteelSeries Arctis Nova 7 Wireless Gen 2 Headset Review - New and Improved, But Is It Enough?
SteelSeries Arctis Nova 7 Wireless Gen 2 Headset Review - New and Improved, But Is It Enough? AMD Ryzen 7 7700X3D Review - Days of Future Past
AMD Ryzen 7 7700X3D Review - Days of Future Past Samsung 990 2TB SSD Review - Ninth Gen QLC at PCIe Gen4 Speeds
Samsung 990 2TB SSD Review - Ninth Gen QLC at PCIe Gen4 Speeds ASUS ExpertBook Ultra (Panther Lake) 14" Business Laptop Review
ASUS ExpertBook Ultra (Panther Lake) 14" Business Laptop Review ASUS ROG Raikiri II Xbox Wireless Controller Review - Ready to Take Control
ASUS ROG Raikiri II Xbox Wireless Controller Review - Ready to Take Control MOZA FMP18 Panel Bundle Review: authentic F/A-18 Hornet cockpit controls for flight sims
MOZA FMP18 Panel Bundle Review: authentic F/A-18 Hornet cockpit controls for flight sims Micron 6600 ION 245.76TB Enterprise SSD Review - Best in Class Programming Speeds
Micron 6600 ION 245.76TB Enterprise SSD Review - Best in Class Programming Speeds MOZA MA3F EFCM Flight Control Module Review: authentic Airbus A320 autopilot panel for simulators
MOZA MA3F EFCM Flight Control Module Review: authentic Airbus A320 autopilot panel for simulators How to Turn Your Windows Laptop Into a Second Monitor with Miracast and Wireless Display in Minutes
How to Turn Your Windows Laptop Into a Second Monitor with Miracast and Wireless Display in Minutes 6 Mistakes to Avoid When Buying a Windows Laptop
6 Mistakes to Avoid When Buying a Windows Laptop I capped Windows Update's bandwidth with Delivery Optimization, and my downloads stopped choking
I capped Windows Update's bandwidth with Delivery Optimization, and my downloads stopped choking I use this decade-old free tool that finds files faster than Windows Search does
I use this decade-old free tool that finds files faster than Windows Search does I install and update most of my apps with this Windows command now, and I stopped downloading sketchy installers
I install and update most of my apps with this Windows command now, and I stopped downloading sketchy installers Hisense U6SF 65-inch MiniLED TV: High Performance Meets Leisurely Convenience
Hisense U6SF 65-inch MiniLED TV: High Performance Meets Leisurely Convenience I stopped digging through Windows menus after I set up this one folder
I stopped digging through Windows menus after I set up this one folder Don't sell your Windows laptop until you do these things
Don't sell your Windows laptop until you do these things 6 PC cleaning mistakes to avoid for safer hardware maintenance
6 PC cleaning mistakes to avoid for safer hardware maintenance Phison and Intel Take Aim at Local AI's Memory Wall with aiDAPTIV
Phison and Intel Take Aim at Local AI's Memory Wall with aiDAPTIV