


Introduction

The latest Haswell-EP Intel Xeon E5-2600 v3 processors are about to be released this month, and we have seen some interesting data on these new processors.
The Xeon E5-2600 v3 processors are based on a "Tock" version of the 2600 v2 processors, and use the new 22nm 3D Transistors process.

Here we get a look at a wafer made up of E5-2699 v3 18-core processors. This was a large wafer, and it sported as many as 90 actual dies on one wafer. It was difficult to get a picture of this wafer where the dies were countable, so our number could be off by a few dies. One thing that we noticed right off the bat was that the dies go all the way to the edges, with plenty of wasted die. If you look at the bottom of this picture, you can spot some dies that hardly have any die showing - some with maybe less than one-eighth of an actual die.

Here we have a slightly closer look at the wafer; actual cores in each package are starting to become clear. The gap between each die is very miniscule, so the tolerance for cutting these dies apart must be very, very small.

This is as close as we could get with a picture of the die on the wafer. Starting on the left hand side, you can see three rows, each containing four cores. Also, notice on the far right side there is one row with six cores. Adding all of these cores up, we get a total of 18 cores on the wafer shot. What concerns us is the larger number of cores on the right side. Having a larger number of cores on the right may cause adverse heating under heavy loads on that side of the processor.
By shifting cores and supporting circuits around a bit, and perhaps making the die itself a little wider, it may just be possible to get 24 cores on a die. However, we are sure Intel has considered this, and this configuration must have been more efficient in the end. Now, let us look at the actual processor packages.

Here we see the respective processor packages. The package on the left is used for smaller core count processors; in this case, an eight-core processor. There is a socket R3 label printed on the substrate. Notice it does not have the side extensions on the substrate.
Our Latest Editorials Article Coverage
The middle package is used for larger core counts; in this case, a 16-core processor is shown. It also has a socket R3 label printed on the substrate. There are two breathing holes on the IHS. You can expect this package would be used for 10, 12, 14, 16, and 18-core SKU's.
The processor on the far right has a label of R1 printed on the substrate. We have not seen a socket 2011-E version of this processor yet; the one shown is of an Ivy Bridge-EX v2 processor. R1 socket is still Socket 2011, but it has different notches that prevent it from being used on a R3 socket, which is typical. We believe these processors are for 4P, or Quad-Socket systems, and we expect a version will be available for the new Haswell-E processors.

Here we can see a picture of the new socket used with the E5-2600 v3 line up. Notice the sides of the socket that allow for the package extension. We found installing these new processors to be interesting, to say the least. The notches at the top and bottom of the package make it somewhat difficult to discern the correct orientation for installation. Take extra care when installing these processors for the first time. The mounting holes are the same used for any Socket 2011 heat sink, so you will not need to change these out for the new platforms.
E5-2600 v3 Platform Summary
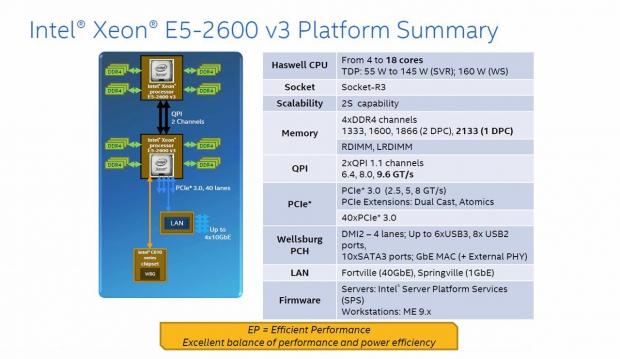
Here we see the specifications for the Xeon E5-2660 v3 processors. There is support provided for four to 18 cores with dual socket capability. TDP ranges from 55W up to 160W for workstations.
Memory is now DDR4, and can give a frequency of up to 2133 MHz. The E5-2600 v3 processors use 2x QPI 1.1 channels with up to 9.6 GT/s. These processors support PCIe 3.0 with up to 8 GT/s and 40 lanes.
The chipset will be Wellsburg PCH. This gives support for a huge number of SATA ports at 10. A large number of USB devices can be used with six USB 3.0 ports, and eight USB 2.0 ports. Wellsburg also supports DMI2 with 4x lanes. We would like to see more than 4x lanes used, but we think we will have to wait for the next Tick in the processor line up.
LAN improvements will have the new Fortville (40 GbE) that can be included.
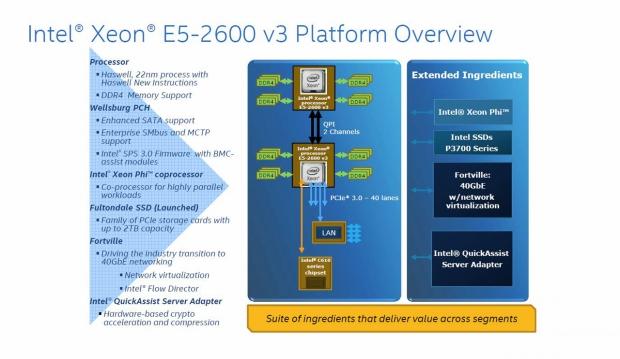
Here we see a platform overview of the E5-2600 v3 line up. The C610 series chipset offers many improvements over the C602 chipset. It includes enhanced SATA support, enterprise SMbus, and MCTP support. In addition, Intel SPS 3.0 firmware with BMC-assist modules is included.
Intel Xeon Phi co-processor and P3700 series PCIe SSD (Fultondale) with storage capacity up to 2TB capacity are also included. For networks, there is a 40GbE network with Fortville, which offers network virtualization, and Intel flow director to give us much faster network capabilities.
Intel QuickAssist Server Adapter offers hardware-based crypto acceleration and compression. This is an add-on card, which offers up to 50 Gbps of crypto acceleration, or up to 20 Gbps of compression in a PCIe slot, low-profile form factor.
Now, let us turn our attention to the projected SKU line up for the E5-2600 v3 processors.

This is the product line up that we know of at this time. There may be spin offs of some of these, as we have seen a few odd SKU's out on the internet. Intel does not disclose SKU's that OEM's have made, so additional SKU's that are used by OEM's will show up on their platforms.
The LLC cache numbers appear to follow a 2.5 MB cache per core in most cases, but some are different, like the E5-2699 v3 with a possible 45 MB cache total. The two basic SKU's, or E5-2609 v3 and E5-2603 v3, do not support hyper-threading and turbo boost. Also, note that not all SKU's support DDR4 memory with 2133 MHz speed.
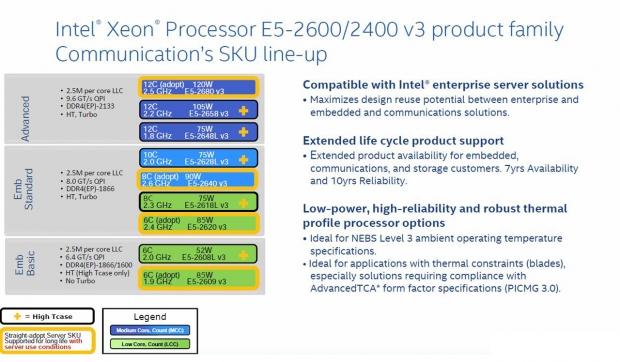
Intel also offers an additional SKU list; these are used for communications and storage servers. The E5-2680 v3, E5-2640 v3, E5-2620 v3, E5-2603 v3, and E5-2695 v3 are labeled as Comms/Storage straight-adopt server SKU, and have support for a long life under server usage model conditions.
E5-2600 v3 Architectural Overview
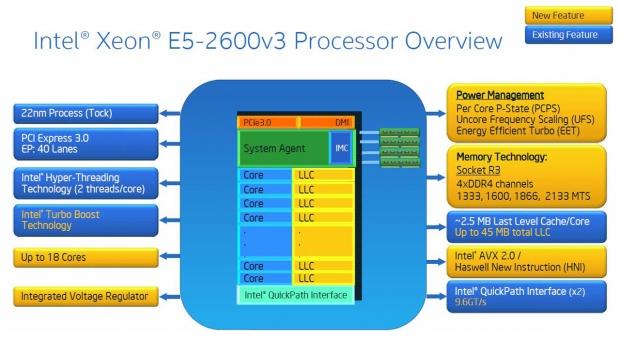
What are the key differences between E5-2600 v2 and E5-2600 v3 processors? Intel has upped the core count from a max of 12 cores on the v2 processors to a max of 18 cores on the v3 processors.
Frequency adjustments have changed from TDP and Turbo, only on the E5 v2 processors, to TDP, Turbo Frequency, and added AVX and AVX Turbo frequencies on the E5 v3's. AVX support and been updated from AVX 1 which was 8 DP (double point) Flops/Clock/Core to AVX2 and 16 DP (double point precision) Flops/Clock/Core.
Memory types have switched from 4x DDR3 Channels RDIMM, UDIMM, and LRDIMM, to 4x DDR4 Channels RDIMM and LRDIMM. Memory Frequency (MHz) has improved from DDR3 1866 (1DPC), 1600, 1333, 1066, to DDR4 operating frequency:
RDIMM: 2133 (1DPC), 1866 (2DPC), 1600
LRDIMM: 2133 (1&2DPC), 1600
In addition, the updated memory controller now supports DDR4, and now has two home agents in more SKU's and directory cache. This increases memory bandwidth and power efficiency, provides greater socket BW with more outstanding requests, and lower average memory latency.
LLC now has Cluster on Die (COD) mode with improved LLC allocation policy, and cache allocation monitoring (Intel Cache Allocation Technology (CAT)). These new additions help to increase performance, reduce latency, and improve performance by better application placement in a VM environment.
Intel Cache Allocation Technology (CAT) enables control over the placement of data in the last-level cache, allowing you to isolate and contain misbehaving threads/apps/VMs, or prioritize more important ones. This feature is available on five specialized communications SKUs in the Xeon E5 v3 generation in a generation-specific way.
QPI Speed has gone up from 8.0 GT/s to 9.6 GT/s. QPI is the on-die interconnects, on which Haswell-EP now has two fully buffered rings that enable higher core counts, and provide higher bandwidth per core. TDP has also changed from up to 130W Server, 150W Workstation to 145W Server, and 160W Workstation, which is increased due to integrated VR.
Power Management has changed from same P-states for all cores, same core and uncore frequency to: Per-core P-States with independent uncore frequency scaling, and energy efficient turbo boost. This will give better performance per watt, and lower socket idle (package C6) power use.
With Integrated IO-Hub (IIO) the LLC cache will track IIO cache line ownership, and increased PCIe buffers and credits. Overall, this will improve PCIe bandwidth under conflicts (concurrent accesses to the same cache line), and increase PCIe bandwidth, and latency tolerance.
Additions to PCIe 3.0 include DualCast, which allows a single write transaction to multiple targets with relaxed ordering. This will minimize memory channel bandwidth, and enable data sent directly to memory, and on the NTB port to help storage applications that are typically memory bandwidth limited.
E5-2600 v3 Architectural Overview Continued
On-Die Interconnects Enhancements and Die Configurations
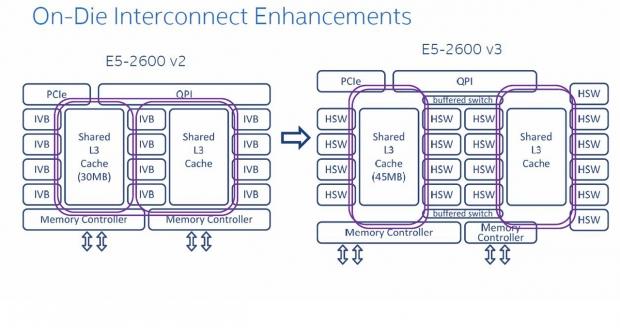
As the core counts started to increase past 12 cores, and more cache added, a more efficient method of connecting all the cores is necessary. The E5-2600 v3's use new ring style interconnects that have bi-directional buffered connections for both rings.
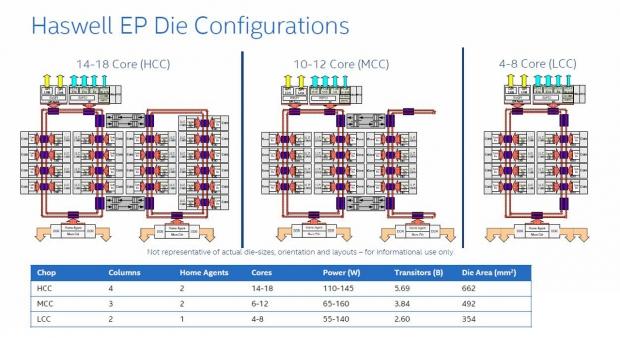
This die configuration chart shows how all cores can communicate with each other. These interconnects allow for faster core communication with a more direct link using dual rings with bi-directional interconnects. These interconnects are also buffered to improve performance.
Integrated Voltage Regulators
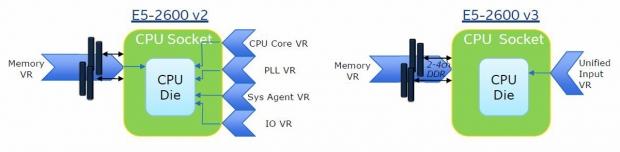
Integrated voltage regulators (IVR) have been simplified, which reduces platform complexity by reducing rails and integration of control.
It also enables a more refined voltage and frequency granularity, faster transitions between power states, and reduces board area to enable factor optimizations.
Turbo and AVX Improvements
Intel Turbo Boost Technology 2.0 will automatically allow processor cores to run faster than the rated and AVX frequencies if they are operating below power, current, and temperature specification limits.
The frequency change with AVX workloads happens when the core detects an AVX instruction; these draw more current, and a higher voltage is needed to sustain these conditions.
The core will signal the Power Control Unit (PCU) to provide more voltage. The core will slow during the execution of the AVX instruction in order to maintain TDP limits, which may cause the frequency to drop. That amount of frequency drop will depend on the workload.
The PCU will signal that the voltage has been adjusted, and cores will return to full execution speed. When finished, the PCU will return to regular (non-AVX) operating modes 1ms after AVX instructions are completed. Turbo state limiting will decrease timing variability and power.
Some HPC software requires limited thread variability, which gives some cluster designers concerns about turbo power surges. To combat this, some disable turbo. Turbo state limiting uniformly caps the maximum number of turbo states for all cores. This provides a predictable range of thread variability and power risk, while allowing some turbo performance benefit.
Cluster On Die (COD) mode

Cluster on Die (COD) is supported on one-socket and two-socket SKU's with two home agents (10+ cores).
COD reduces coherence traffic and cache-to-cache transfer latencies, and targets NUMA (non-uniform memory access) optimized workloads where latency is more important than sharing caching agents. COD is best used for highly NUMA (non-uniform memory access) optimized workloads.
Each Home agent has ~14KB of cache, which is eight-way, 256 sets, and two-sector wide. It stores eight-bit presence vector tracking caching agent, potentially owning a copy a cache line. Allocation on a cache-to-cache transfer and tracks hit-M, hit-E, and hit-S lines, which are hotly contested cache lines.
The result is lower cache-to-cache transfer latencies, and reduced directory updates and reads of hotly contested lines. Snoop traffic is also reduced by sending directed snoops, rather than broadcasting them.
Virtualization (VT-x) Features
The new VM features lower entry/exit latency, which reduces VMM overhead, and increases overall virtualization performance.
VM control structure (VMCS) shadowing enables efficient nested VMM usages, such as manageability and VM protection. Extended page and table (EPT) access/dirty bits enables efficient live migration, and helps SW managed fault tolerant solutions. Intel Cache Allocation Technology (CAT) is now monitored on a per-VM basis. Utilization data allows VM software to make better decisions on workload scheduling and migration.
Advanced Vector Extensions (AVX) 2.0

Advanced Vector Extensions (AVX), has also been updated to AVX2, which now uses 256-bit floating point SIMD instructions. This will allow you to use up to twice the amount of packed data with a single instruction.

AVX2 increases parallelism and throughput in floating point SIMD calculations, and reduces register load. This can be useful for floating-point intensive calculations in multimedia, scientific, financial applications, image & signal processing, and cryptology workloads.
Power Efficiency Improvements
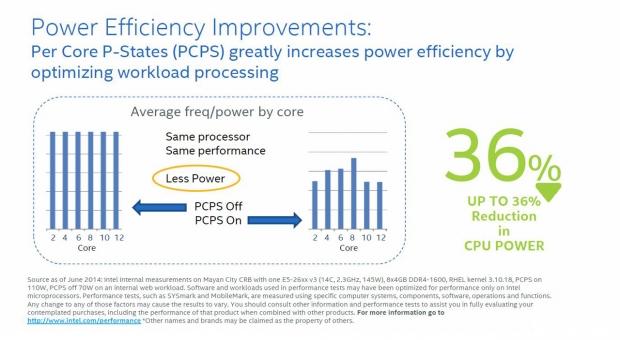
Per-Core P-States (PCPS) allow cores to run at individual frequencies/voltages. Energy efficient turbo mode (EET) monitors stall behavior and increases throughput. Uncore voltage/frequency scaling (USF) in Nehalem would allow cores to turbo up, but uncore would remain at a fixed frequency; Sandy Bridge core and uncore turbo up and down together.
With Haswell-EP, each core and uncore, are now treated independently. Core bound applications can drive frequency higher without needing to increase uncore. LLC/Memory bound applications can drive frequency higher without burning core power.
Intel Cache Monitoring Technology (CMT)
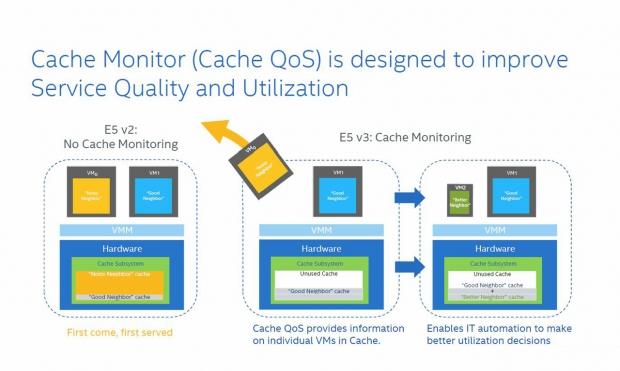
When many VM's are running in a system, the cache can be trashed by what is now called a "noisy neighbor." This VM starts to demand a heavy workload, and has high cache usage. The new demand on the cache starts to degrade performance of VM's running on the same cores/cache. The heavy load of the noisy neighbor starts to degrade the performance of normal acting VMs.
Today, the VMs that require heavy system use are often moved to areas that have the resources to support them, so other normal VMs can continue without being adversely affected by the noisy neighbor.
With Intel Cache Monitoring Technology, the processor is able to detect this, and even move the VM when needed. System Cache can also be partitioned, so the noisy neighbor will have a lesser impact on the VMs around it.
Intel Cache Monitoring Technology (CMT) enables monitoring of last-level cache occupancy on a per-thread/app/VM basis, enabling measurement of application cache sensitivity, profiling, fingerprinting, chargeback models, detection of cache-starved apps/VMs, detection of "noisy neighbors" (which hog the LLC) and advanced cache-aware scheduling policies. The CMT feature is supported on all Xeon E5 v3 SKUs and is enumerated via CPUID.
The DDR4 Difference
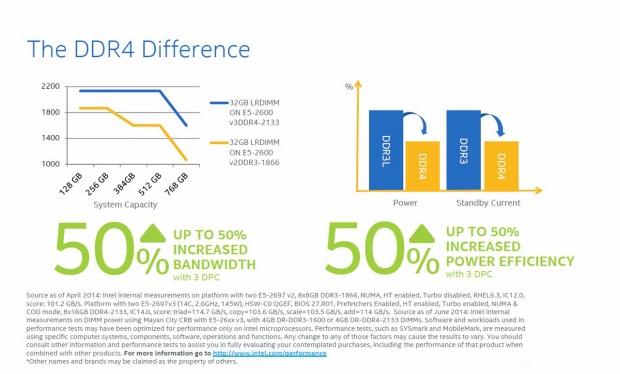
The move to DDR4 has many benefits. First, power dropped from 1.5v in DDR3 down to 1.2v with DDR4. There is also smaller page size (1024 -> 512) for x4 devices. This can show a savings of ~2W per DIMM at the wall.
Improved RAS enables better command/address parity error recovery. When multiple DIMMs per channel are installed, DDR4 has higher bandwidth, and increased DIMM frequency.

When 4x DIMMs are installed per CPU, we can maintain higher DIMM speeds. If 8x DIMMs are installed, frequency will drop to the next rated frequency. Larger capacity DDR4 DIMMs will be available so that using four channels will support a larger amount of RAM, at a faster speed.
Intel Communications Platform
Intel's Communications Platform offers new capabilities that include Open Source QuickAssist Enabling, and software packet processing optimizations.
The new platform improvements will effect infrastructure such as routers, gateways, and security appliances. Other areas are cloud computing, storage, networking, web, mail, secure search, VPN, and firewalls.
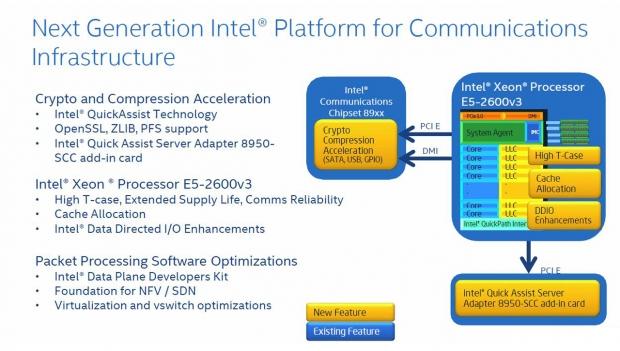
This SKU line offers extended product availability for embedded, communications, and storage applications with 7 years' availability, and 10 years' reliability.
The Communication SKU line-up offers low-power use and high reliability. Optimized thermal profiles are ideal for NEBS Level three ambient operating temperatures. Applications with thermal constraints such as blade servers are ideal for these SKU's. Compliance with AdvancedTCA form factor specifications (PICMG 3.0) is also offered.
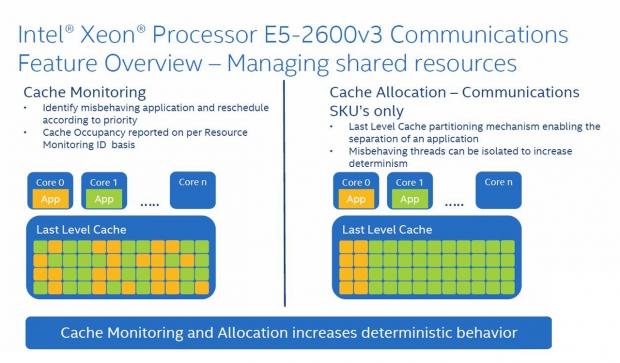
In the chart above, we can see that misbehaving applications can affect the performance of other applications. Cache monitoring can detect this, enable separation of applications and misbehaving threads, isolate them, and increase determinism.
Cache partitioning enables separation of applications to their own partition of cache to keep cache from being scattered by a misbehaving application/thread.
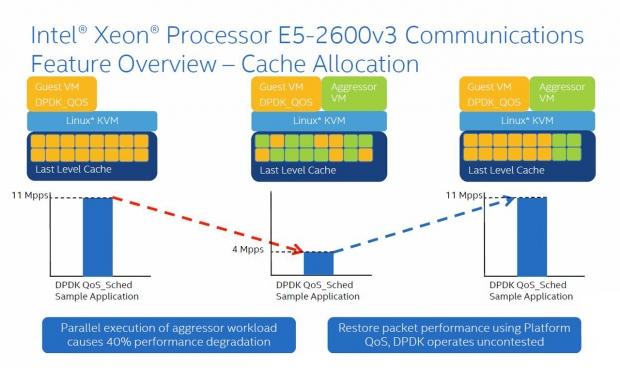
This chart shows how an aggressor VM can start to degrade performance until cache monitoring detects this, partitions the cache, and restores packet performance.
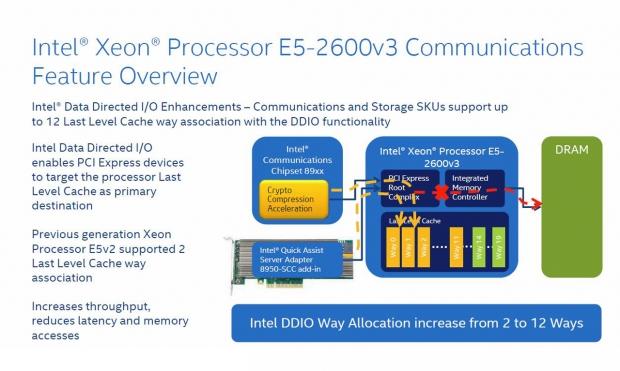
Intel Data Direct I/O Enhancements to the Communication SKU line enables PCIe devices to target the processor's last level cache as a primary destination. Previous E5 v2 only supported two last levels, while E5 v3 supports 12 last levels.

The Intel QuickAssist Adapter 8950 provides crypto-acceleration, and compression acceleration.
Benefits of QuickAssist Adapters include provided hardware acceleration services for cryptographic and compression performance, and functions provided for Public key, cryptography, and random number generation. The Intel QuickAssist Adapter 8950 comes in a standard and low profile PCIe expansion card, without the need for propriety form factor solutions.
Test System Setup

We would like to thank Sandisk,Crucial,Noctua,Supermicro,ASRock Rack,NZXT,Yokogawa, and AIDA64 for their support in providing parts for our test system.
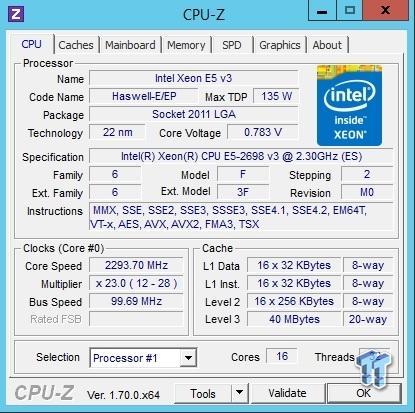
The test setup is typical for a server setup. The CPU used in these tests is a pair of Intel Xeon E5-2698 v3 CPU's (16-core). The memory installed is 64 GB of Crucial DDR4 2133 MHz CL15 RAM.
For all tests that were run, we used optimized BIOS settings.
System and CPU Benchmarks
Cinebench 11.5
CINEBENCH is a real-world, cross platform test suite that evaluates your computer's performance capabilities. The test scenario uses all of your system's processing power to render a photorealistic 3D scene. This scene makes use of various different algorithms to stress all available processor cores. You can also run this test with a single core mode to give a single core rating.
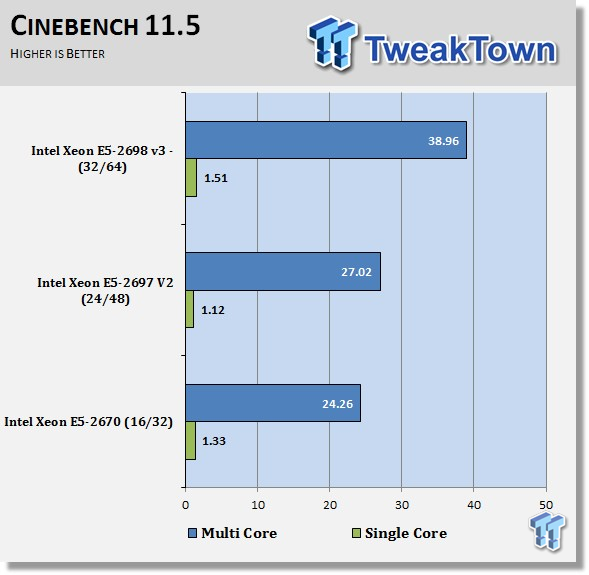
Cinebench demonstrates platform computational capability for the E5-2698 v3's. Here we see a large improvement using this processor. Cinebench uses all 64 threads available in the benchmark to great advantage. You can also see how well processors have scale up with added cores to the die.
Some have reported that using E5-2699 v3 with 18 cores have reached scores of 42+ in this benchmark, which shows even better scaling.
Cinebench R15
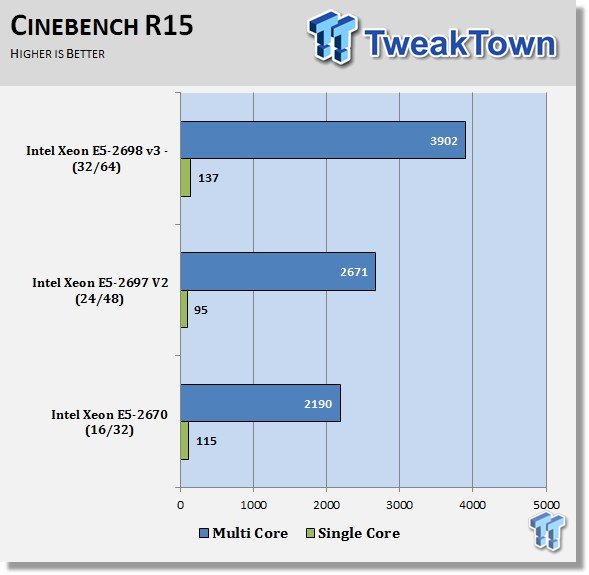
Just like in the Cinebench 11.5 results, we see a lower single threaded score, and a much higher multi-threaded score. The E5-2698 v3 scales up very well with all the extra cores.
wPrime
wPrime is a leading multi-threaded benchmark for x86 processors that tests your processor performance. This is a great test to use to rate the system speed; it also works as a stress test to see how well the system cooling is performing.
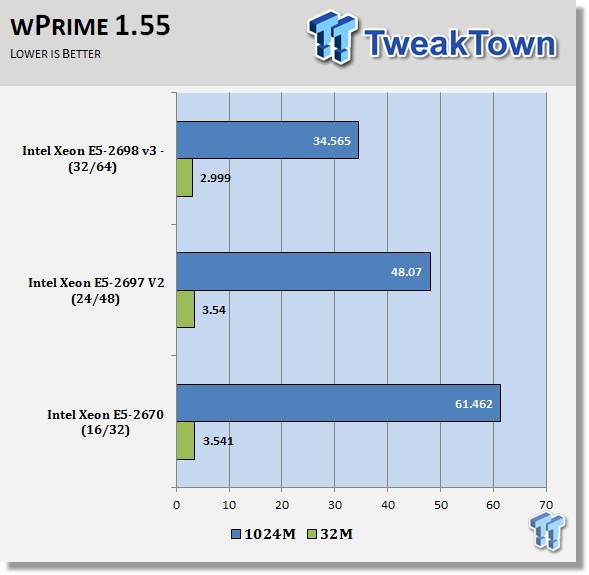
In this test, we see the E5-2698 v3's really speed up wPrime execution times. AVX2 really helps with this benchmark's performance.
Linpack
Intel Optimized LINPACK Benchmark is a generalization of the LINPACK 1000 benchmark. It solves a dense (real*8) system of linear equations (Ax=b), measures the amount of time it takes to factor and solve the system, converts that time into a performance rate, and tests the results for accuracy.
Linpack is a measure of a computer's floating-point rate of execution ability, measured in GFlops (Floating-point Operations per Second), 10 billion FLOPS = 10 GFLOPS.
Linpack is a very heavy compute application that can take advantage of the new AVX2 instruction. As it puts a very high load on the system, it is also a good stress test program.
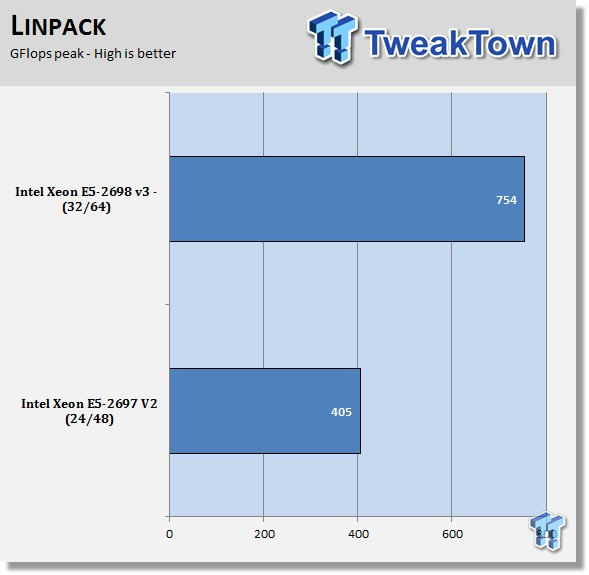
The E5-2698 v3 processors and AVX2 really take off in this benchmark with almost double the performance of E5-2697 v2 processors. We have also seen results as high as 800 GFlops using E5-2699 v3 processors.
Memory Benchmarks
AIDA64
AIDA64 memory bandwidth benchmarks (Memory Read, Memory Write, and Memory Copy) measure the maximum achievable memory data transfer bandwidth.
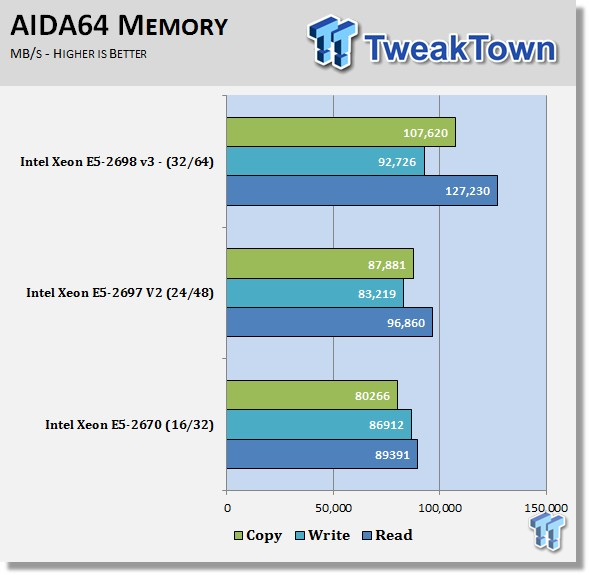
AIDA64 memory tests show the Crucial DDR4 2133 MHz improving memory bandwidth in the Read and Copy tests.
However, we do not see good scaling in the Write tests. At this time we are not sure why this is; it could be testing software needs updating, or it could be there are issues with the IMC on the E5 v3's processors. We plan to test this further to see if we can spot just what the issue might be.
DDR4 also offers improvements in latency over DDR3, which we saw around 90-103ns. With DDR4, we see a big improvement with latency dropping to around 77ns. Faster memory and lower latency with higher capacities offer higher performance for memory driven applications.
Power Consumption and Final Thoughts
Power Consumption
We have upgraded our power testing equipment, and now use a Yokogawa WT310 power meter for testing. The Yokogawa WT310 feeds its data through a USB cable to another machine where we can capture the test results.
To test total system power use, we used AIDA64 Stability test to load the CPU, and then recorded the results. Also, we now add in the power use for a server from off state, up to the point of hitting the power button to turn it on, and taking it all the way to the desktop. This gives us data on power consumption during the boot up process.
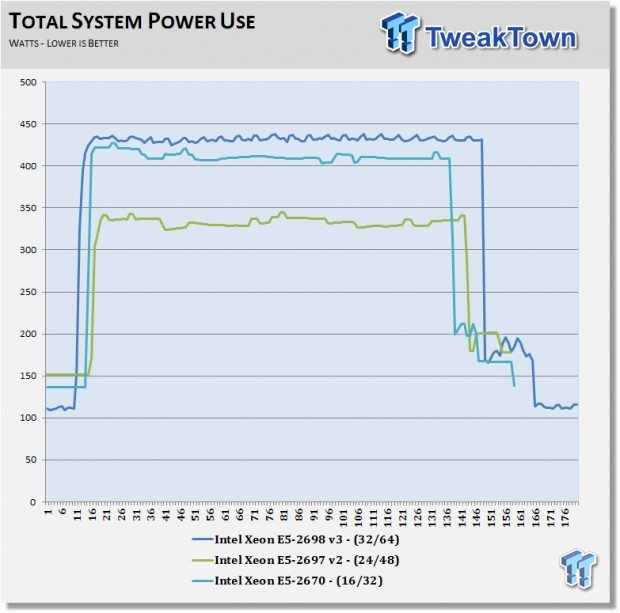
This is our basic power test that we use on all our motherboard and systems tests. Factors that effect this test are the amount of RAM installed and the number of onboard options such as storage controllers or network adapters.
We do notice that the Haswell-EP system has a much lower power use running at idle with the new E5 v3 processors. Power scaling over the list of processors has steadily gone down over the years, and now we see a dual socket system using ~100watts at idle, in comparison to 150watts with last gen E5 v2s. The E5-2697 v2 seems to be in a good spot as far as max load power use, but falls off a great deal when it drops back to idle. We will have to get a larger sampling of motherboards to get a feel for how the E5 v3s behave with power use.
Final Thoughts
Clearly, the biggest advantage of the new Haswell-EP processors is the increased number of cores. We think that in itself is a huge benefit to many systems that are in use today.
Adding a large number of cores to a package also creates core communication problems. The new On-Die Interconnects create simplified paths for data to travel from one core to another. Going from core 18 to core one and moving data from memory now takes a shorter path through buffered bi-directional interconnects. This lowers latency, improves response time, and increases performance for applications.
In our testing, we see very good scaling with the added cores that the E5 v3s provide. Turning on hyper-threading does not always scale as we would like to see. Some benchmarks run better with HT off and forcing the number of threads before the run. This is not something new though; many applications used in the enterprise area prefer HT turned off, as it does add a small amount of latency.
We also looked at how the new Turbo Boost performs. It does appear to kick in faster here than on the E5 v2's, and overall, it gives good results. The new Per-Core P-States (PCPS) also help to reduce power consumption a great deal. The effects of these features lowered power use to just over 100watts on some systems we tested, which is impressive for a dual socket system. In the data center, power consumption can be a real issue, now the new E5 v3 processors and DDR4 can help to lower power use.
What we think will really benefits data centers are the new features for handling VM environments. Intel has taken big steps to make VMs easier to manage, and reduce the effects of "noisy neighbors."
We were up at Intel Jones Farm in Oregon last month, and watched a demo showing how this works. The demo machine had something in the order of 12 VMs running. When one VM became very heavily loaded, you could see performance degrade across the rest of the VMs. The new features like Cache Monitoring (Cache QoS), detected this, and at that point the aggressor VM was given its own cache partition and performance was restored.
The new DDR4 memory also has a big impact on system performance. We can now install DIMMs with larger capacity in less slots. This helps to keep RAM speeds higher, as we do not need to spread the RAM out into smaller capacity DIMMs. Even with a max RAM, load out speed is still double what it was with DDR3.
Intel Advanced Vector Extensions (AVX), now updated with the new AVX2, show a huge boost to floating point bandwidth. We see close to double the bandwidth in our Linpack tests. With the growing amount of encrypted and compressed data, AVX2 shows good results in speeding these processes up. Not everything is all nice and shiny with E5-v3 processors though. In August 2014, Intel announced a bug in the TSX implementation on Haswell and early Broadwell CPUs, which resulted in disabling the TSX feature on affected CPUs via a microcode update.
Transactional Synchronization Extensions (TSX) is an extension to the x86 instruction set architecture that adds hardware transactional memory support, speeding up execution of multi-threaded software through Hardware Lock Elision (HLE). Intel stated that this instruction would not have a big impact on current code, but plans to update silicon in the next processor stepping, but gives no eta on this fix.
Overall, we can see big performance boosts with the new Haswell-EP processors. Intel has addressed many problems with power use, multi-core processing, and VM applications. The new systems offer much needed performance improvements for today's heavy VM environments.
 Micron 6600 ION 245.76TB Enterprise SSD Review - Best in Class Programming Speeds
Micron 6600 ION 245.76TB Enterprise SSD Review - Best in Class Programming Speeds Memblaze PBlaze 7 7A40 Ocean 61.44TB Enterprise SSD Review - Oceans of QLC at 3.3 million IOPS
Memblaze PBlaze 7 7A40 Ocean 61.44TB Enterprise SSD Review - Oceans of QLC at 3.3 million IOPS KIOXIA CD9P-R 7.68TB E3.S Review - The Best-In-Class Data Center SSD
KIOXIA CD9P-R 7.68TB E3.S Review - The Best-In-Class Data Center SSD DapuStor Roealsen6 R6060 E1.L 245.76TB SSD Review - Massive Capacity with Fast Retrieval
DapuStor Roealsen6 R6060 E1.L 245.76TB SSD Review - Massive Capacity with Fast Retrieval Phison Pascari X200P 7.68TB Enterprise SSD Review - Sequential Read Champion
Phison Pascari X200P 7.68TB Enterprise SSD Review - Sequential Read Champion Der8auer strips the AIO out of a $7,000 RTX 5090 Lightning and replaces it with a custom loop, achieving 55C at 800W
Der8auer strips the AIO out of a $7,000 RTX 5090 Lightning and replaces it with a custom loop, achieving 55C at 800W Modder straps a 2.5kg heatsink to an RTX 4060 for completely fanless cooling
Modder straps a 2.5kg heatsink to an RTX 4060 for completely fanless cooling Redditor builds his own PS4 handheld, the 'PS4P' has a 1080p screen and a cooling fan from a GTX 750
Redditor builds his own PS4 handheld, the 'PS4P' has a 1080p screen and a cooling fan from a GTX 750 Sony's PS6 controller could feature a touchscreen display and fully modular inputs, according to a new patent
Sony's PS6 controller could feature a touchscreen display and fully modular inputs, according to a new patent Marathon loses game director as Bungie shifts to PvE model
Marathon loses game director as Bungie shifts to PvE model Bethesda's Todd Howard no longer thinks about retirement
Bethesda's Todd Howard no longer thinks about retirement $30 Quadro M4000 8GB from 2015 plays Cyberpunk 2077 at almost 60 FPS with an overclock
$30 Quadro M4000 8GB from 2015 plays Cyberpunk 2077 at almost 60 FPS with an overclock Valve replaces stolen Steam Machine after Royal Mail left £1,000 package on a doorstep
Valve replaces stolen Steam Machine after Royal Mail left £1,000 package on a doorstep Former GTA V producer says Rockstar cut fully finished minigames and entire levels that 'just disappeared'
Former GTA V producer says Rockstar cut fully finished minigames and entire levels that 'just disappeared' Elon Musk responds to $52 billion deal between SpaceX and Foxconn for insane NVIDIA compute
Elon Musk responds to $52 billion deal between SpaceX and Foxconn for insane NVIDIA compute SteelSeries Arctis Nova Pro Omni Wireless Headset Review - One Headset to Rule Them All
SteelSeries Arctis Nova Pro Omni Wireless Headset Review - One Headset to Rule Them All SteelSeries Arctis Nova 7 Wireless Gen 2 Headset Review - New and Improved, But Is It Enough?
SteelSeries Arctis Nova 7 Wireless Gen 2 Headset Review - New and Improved, But Is It Enough? AMD Ryzen 7 7700X3D Review - Days of Future Past
AMD Ryzen 7 7700X3D Review - Days of Future Past Samsung 990 2TB SSD Review - Ninth Gen QLC at PCIe Gen4 Speeds
Samsung 990 2TB SSD Review - Ninth Gen QLC at PCIe Gen4 Speeds ASUS ExpertBook Ultra (Panther Lake) 14" Business Laptop Review
ASUS ExpertBook Ultra (Panther Lake) 14" Business Laptop Review ASUS ROG Raikiri II Xbox Wireless Controller Review - Ready to Take Control
ASUS ROG Raikiri II Xbox Wireless Controller Review - Ready to Take Control MOZA FMP18 Panel Bundle Review: authentic F/A-18 Hornet cockpit controls for flight sims
MOZA FMP18 Panel Bundle Review: authentic F/A-18 Hornet cockpit controls for flight sims MOZA MA3F EFCM Flight Control Module Review: authentic Airbus A320 autopilot panel for simulators
MOZA MA3F EFCM Flight Control Module Review: authentic Airbus A320 autopilot panel for simulators Turtle Beach Stealth Pro II Wireless Gaming Headset Review - Premium Sound, Fantastic Features
Turtle Beach Stealth Pro II Wireless Gaming Headset Review - Premium Sound, Fantastic Features I use this decade-old free tool that finds files faster than Windows Search does
I use this decade-old free tool that finds files faster than Windows Search does I install and update most of my apps with this Windows command now, and I stopped downloading sketchy installers
I install and update most of my apps with this Windows command now, and I stopped downloading sketchy installers Hisense U6SF 65-inch MiniLED TV: High Performance Meets Leisurely Convenience
Hisense U6SF 65-inch MiniLED TV: High Performance Meets Leisurely Convenience I stopped digging through Windows menus after I set up this one folder
I stopped digging through Windows menus after I set up this one folder Don't sell your Windows laptop until you do these things
Don't sell your Windows laptop until you do these things 6 PC cleaning mistakes to avoid for safer hardware maintenance
6 PC cleaning mistakes to avoid for safer hardware maintenance Phison and Intel Take Aim at Local AI's Memory Wall with aiDAPTIV
Phison and Intel Take Aim at Local AI's Memory Wall with aiDAPTIV How to Remap Keyboard Keys in Windows using Microsoft PowerToys
How to Remap Keyboard Keys in Windows using Microsoft PowerToys 7 tips to organize your Windows files for faster, easier access
7 tips to organize your Windows files for faster, easier access Intel Arc G3 Extreme first impressions with MSI's Claw 8 EX AI+ - Incredible power for an extreme price
Intel Arc G3 Extreme first impressions with MSI's Claw 8 EX AI+ - Incredible power for an extreme price