



NVIDIA's next-gen Hopper GPU architecture is one of the most monsterous pieces of technology the human race has ever created... but it wasn't just humans... artificial intelligence (AI) helped in a huge uway, too.
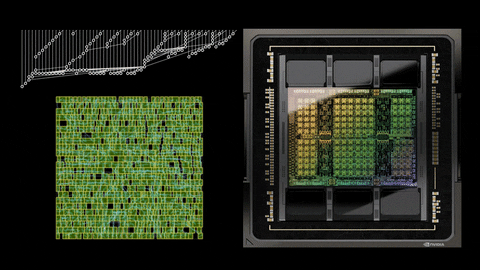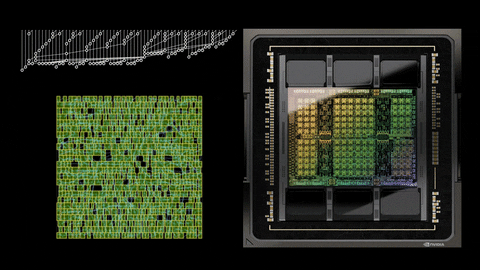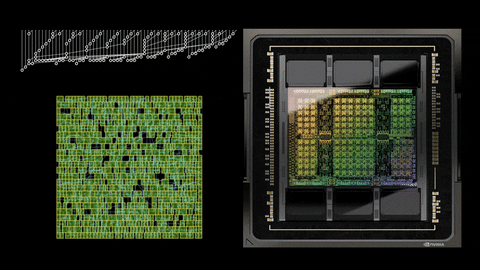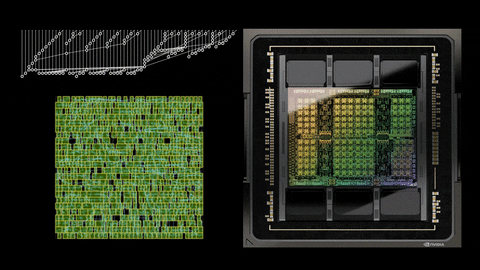
In a recent post on NVIDIA's own Developer website, the company underlines how it used AI to design the greatest GPU it has created so far: the new NVIDIA Hopper H100 GPU. NVIDIA normally designs most of its next-gen GPUs using Electronic Design Automation (EDA) tools, but AI helped out with Hopper H100 through the PrefixRL methodology, which is an optimization of Parallel Prefix Circuits using Deep Reinforcement Learning. This allows NVIDIA to design smaller, faster, and more power-efficient GPUs... all while having more performance.
Rajarshi Roy, Applied Deep Learning Research at NVIDIA, tweeted: "Arithmetic circuits were once the craft of human experts, and are now designed by AI in NVIDIA GPUs. H100 chips have nearly 13,000 AI designed circuits! How is this possible?" and then posted a link to the blog that he co-wrote on NVIDIA's website.
The authors explain: "Arithmetic circuits in computer chips are constructed using a network of logic gates (like NAND, NOR, and XOR) and wires. The desirable circuit should have the following characteristics:"
- Small: A lower area so that more circuits can fit on a chip.
- Fast: A lower delay to improve the performance of the chip.
- Consume less power: A lower power consumption of the chip.
NVIDIA has said that it used this method to design close to 13,000 AI-assisted circuits, which offer a 25% area reduction when put up against EDA tools (which are just as fast, and just as functionally the same as the new method powered by AI).
- Read more: NVIDIA H100 SXM in the flesh: 4nm Hopper GPU + 80GB HBM3 memory
- Read more: You can buy NVIDIA's next-gen Hopper GPU + 80GB HBM2e for $36,550
- Read more: NVIDIA H100 GPU full details: TSMC N4, HBM3, PCIe 5.0, 700W TDP, more
- Read more: NVIDIA reveals next-gen Hopper GPU architecture, H100 GPU announced
- Read more: NVIDIA can sustain the world's internet traffic with 20 x H100 GPUs
PrefixRL is said to be a very computational demanding task, where it uses 256 CPUs and 32,000 GPU hours for each and every physical simulation of each GPU. NVIDIA worked on this too, of course, developing "Raptor", which is NVIDIA's new in-house distributed reinforcement learning platform that taps NVIDIA hardware for this very thing.
- Raptor's ability to switch between NCCL for point-to-point transfer to transfer model parameters directly from the learner GPU to an inference GPU.
- Redis for asynchronous and smaller messages such as rewards or statistics.
- A JIT-compiled RPC to handle high volume and low latency requests such as uploading experience data.


 Planning begins for world's most powerful GPU cluster with 100,000
Planning begins for world's most powerful GPU cluster with 100,000 Intel discounting new Gaudi 3 AI accelerator: $16K against NVIDIA H100 AI GPU for $30K+
Intel discounting new Gaudi 3 AI accelerator: $16K against NVIDIA H100 AI GPU for $30K+ AMD preps China-specific AI chip to battle NVIDIA, Huawei: cut-down Radeon AI PRO R9700 rumored
AMD preps China-specific AI chip to battle NVIDIA, Huawei: cut-down Radeon AI PRO R9700 rumored Elon Musk teases Colossus: most powerful AI training system uses 100,000 NVIDIA H100 AI GPUs
Elon Musk teases Colossus: most powerful AI training system uses 100,000 NVIDIA H100 AI GPUs NVIDIA to deep dive into the Blackwell GPU architecture at Hot Chips 2024 next week
NVIDIA to deep dive into the Blackwell GPU architecture at Hot Chips 2024 next week HDMI 2.2 products are coming in 2027 as chip makers begin sampling FRL2 silicon this year
HDMI 2.2 products are coming in 2027 as chip makers begin sampling FRL2 silicon this year Solo dev tries to make his own GTA 6 with AI, as he got tired of waiting for Rockstar
Solo dev tries to make his own GTA 6 with AI, as he got tired of waiting for Rockstar Repair channel buys ASUS RTX 4090 for $222 and finds plastic die with fake NVIDIA markings
Repair channel buys ASUS RTX 4090 for $222 and finds plastic die with fake NVIDIA markings Epic's gen AI use deters partners, Vampire Survivors x Fortnite might get cancelled
Epic's gen AI use deters partners, Vampire Survivors x Fortnite might get cancelled Sony seems to confirm singleplayer first-party PlayStation games will remain console exclusive
Sony seems to confirm singleplayer first-party PlayStation games will remain console exclusive NVIDIA GeForce GTX 1650 modded with 8GB of GDDR6 memory doubles performance in God of War and Unigine Superposition
NVIDIA GeForce GTX 1650 modded with 8GB of GDDR6 memory doubles performance in God of War and Unigine Superposition Apple will be working with Intel to design and build its chips in the USA, confirms President Donald Trump
Apple will be working with Intel to design and build its chips in the USA, confirms President Donald Trump GTA 6 pre-order date revealed by Rockstar
GTA 6 pre-order date revealed by Rockstar Anthropic's CEO confirms he can be fired as CEO through the company's own authority
Anthropic's CEO confirms he can be fired as CEO through the company's own authority Speed Racer (2008) 4K Ultra HD Blu-ray Review: a stunning remaster of the cult classic
Speed Racer (2008) 4K Ultra HD Blu-ray Review: a stunning remaster of the cult classic MOAIPLAY ORA PRO G1 850W ATX 3.1 PSU Review: high efficiency and 10-year warranty for $119.99
MOAIPLAY ORA PRO G1 850W ATX 3.1 PSU Review: high efficiency and 10-year warranty for $119.99 Navman MiVue Smart True 4K Surround Dashcam Review - Seeing In All Directions At Once
Navman MiVue Smart True 4K Surround Dashcam Review - Seeing In All Directions At Once IQUNIX Magi96 Pro Aluminum Low Profile Mechanical Keyboard Review - Premium Build, Satisfying Sound
IQUNIX Magi96 Pro Aluminum Low Profile Mechanical Keyboard Review - Premium Build, Satisfying Sound Asetek Forte S-Series Racing Simulator Bundle Review
Asetek Forte S-Series Racing Simulator Bundle Review Razer Pro Type Ergo Wireless Split Ergonomic Keyboard Review - Built for Comfort and Support
Razer Pro Type Ergo Wireless Split Ergonomic Keyboard Review - Built for Comfort and Support ASUS ROG Strix Morph 96 Wireless Gaming Keyboard Review - Great Performance, More Affordable
ASUS ROG Strix Morph 96 Wireless Gaming Keyboard Review - Great Performance, More Affordable SAPPHIRE Radeon RX 9070 GRE PULSE OC Review - A New 1440p Challenger Has Arrived
SAPPHIRE Radeon RX 9070 GRE PULSE OC Review - A New 1440p Challenger Has Arrived NZXT H6 RGB+ Compact Dual-Chamber Chassis Review
NZXT H6 RGB+ Compact Dual-Chamber Chassis Review ASRock Radeon RX 9070 GRE Steel Legend Review - The RDNA 4 Mid-Range Reshuffle
ASRock Radeon RX 9070 GRE Steel Legend Review - The RDNA 4 Mid-Range Reshuffle I read the Windows Backup app screen carefully, and it does not back up what most people think
I read the Windows Backup app screen carefully, and it does not back up what most people think Low Sound Volume on Windows 11? How to fix audio issues and restore normal volume
Low Sound Volume on Windows 11? How to fix audio issues and restore normal volume 8 Critical Warning Signs You Should Never Ignore in Windows 11
8 Critical Warning Signs You Should Never Ignore in Windows 11 This Windows security feature protects Documents from ransomware, but it is off by default
This Windows security feature protects Documents from ransomware, but it is off by default Windows 11 already has a voice typing tool, and it is the one most people are not using
Windows 11 already has a voice typing tool, and it is the one most people are not using Quick Assist is the only remote-support tool I open when a relative calls about their PC
Quick Assist is the only remote-support tool I open when a relative calls about their PC The PowerToys utilities I keep enabled on every Windows 11 PC, and the ones I turned off within a week
The PowerToys utilities I keep enabled on every Windows 11 PC, and the ones I turned off within a week TweakTown's Best of Computex 2026 Awards - The Best Hardware, Gaming Gear, and AI
TweakTown's Best of Computex 2026 Awards - The Best Hardware, Gaming Gear, and AI Phison E37T SSD Controller Exclusive Preview - The Fastest DRAMless SSD Platform Yet
Phison E37T SSD Controller Exclusive Preview - The Fastest DRAMless SSD Platform Yet