




NVIDIA's industry-leading H100 Tensor Core GPUs have set new records in the latest industry-standard tests, flexing their AI GPU muscle in the latest MLPerf industry benchmarks.
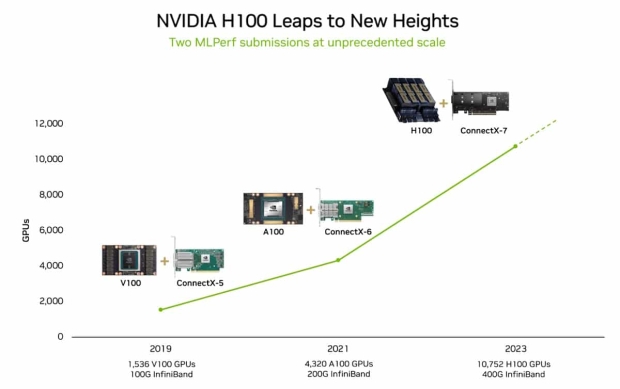
The NVIDIA Eos AI supercomputer packs an incredible 10,752 NVIDIA H100 Tensor Core GPUs and NVIDIA's Quantum-2 InfiniBand networking, which has just completed a training benchmark based on the GPT-3 model with 175 billion parameters trained on 1 billion tokens in just 3.9 minutes. It might not sound like much, but that's nearly 3x faster than the previous world record that NVIDIA set with 10.9 minutes. That's a full 7 minutes shaved off.
The MLPerf benchmark uses a part of the full GPT-3 data set that powers the super-popular ChatGPT service, with NVIDIA teasing its Eos AI supercomputer could train in just 8 days, which is a mind-blowing 73x faster than the previous state-of-the-art system powered by 512 NVIDIA A100 GPUs. The huge speed-up in training time means reduced costs, energy savings, and super-speeds the time-to-market for companies using NVIDIA H100 AI GPUs for their AI products.
NVIDIA talks about new generative AI tests powered by 1024 NVIDIA H100 GPUs that completed a training benchmark based on the Stable Diffusion text-to-image model in just 2.5 minutes, which sets a "high bar" on this new workload, according to NVIDIA.
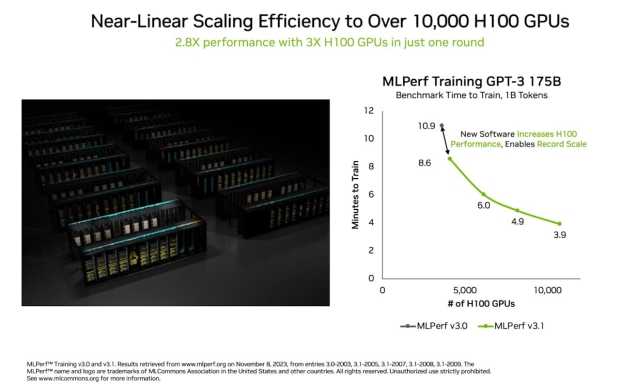
Before this new record-setting benchmark, the previous record for MLPerf was powered by 3584 NVIDIA H100 AI GPUs, while the new record uses way more AI silicon with 10,752 NVIDIA H100 GPUs, a 3x increase in H100 AI GPUs. That 3x increase in GPU numbers delivers a 2.8x scaling in performance and a 93% efficiency rate, which NVIDIA says is also thanks partly to software optimizations.
Efficient scaling is very important for generative AI because LLMs (large language models) are growing by an order of magnitude every year, whereas NVIDIA is the only company in the world with AI GPUs that are up to the task of meeting the insatiable AI GPU demand.
The new world-record MLPerf benchmark is thanks to a full-stack platform of innovators in accelerators, systems and software that both NVIDIA's Eos AI supercomputer and Microsoft Azure used in the latest round. Microsoft's new Azure supercomputer is also powered by the same number of AI hardware, with 10,752 NVIDIA H100 AI GPUs inside.

Now that NVIDIA has two identical H100 AI GPU deployments in the 10,752 GPU milestone, they can look at both of the new 10,752 H100 AI GPUs in either system with MLPerf Training GPT-3 175B. The NVIDIA Eos AI supercomputer hits 3.9 seconds, while the Microsoft Azure ND H100 v5 AI supercomputer is just 0.1 seconds behind at 4.0 seconds. 10.9 seconds for the 3584 H100 AI GPUs, remember.
NVIDIA also set new records in this round, in addition to making advances in generative AI. The company says that H100 GPUs were 1.6x faster than the prior-round training recommender models widely employed to help users find what they're looking for online. RetinaNet, a computer vision model, is up to 1.8x faster now. These increases are thanks to a combination of advances in software and scaled-up hardware.

NVIDIA also points out something important: they were the only company to run all MLPerf tests, with the H100 GPUs used in the fastest performance and the greatest scaling in each of the 9 benchmarks run. Impressive for NVIDIA, and something they should be very proud of indeed.
There were 11 system makers that were using the NVIDIA AI platforms in their submissions this time around, with ASUS, Dell Technologies, Fujitsu, GIGABYTE, Lenovo, QCT, and Supermicro. These companies use the MLPerf benchmark because they know it's a valuable tool for customers evaluating AI platforms and vendors.

 NVIDIA Blackwell AI GPUs up to 2.2x faster than Hopper in MLPerf v4.1 AI training benchmarks
NVIDIA Blackwell AI GPUs up to 2.2x faster than Hopper in MLPerf v4.1 AI training benchmarks NVIDIA shows off its beefed-up H200 AI GPU beating AMD's just-released Instinct MI300X
NVIDIA shows off its beefed-up H200 AI GPU beating AMD's just-released Instinct MI300X Meta using over 100,000 NVIDIA H100 AI GPUs for Llama 4, Zuck: 'bigger than anything I've seen'
Meta using over 100,000 NVIDIA H100 AI GPUs for Llama 4, Zuck: 'bigger than anything I've seen' DeepSeek's new AI assistant app is the top free app on the Apple App Store, ahead of ChatGPT
DeepSeek's new AI assistant app is the top free app on the Apple App Store, ahead of ChatGPT Mark Zuckerberg teases $65B plan on building 1.3 million AI GPU datacenter in 2025
Mark Zuckerberg teases $65B plan on building 1.3 million AI GPU datacenter in 2025 MetaPCs launches first SteamOS 3 prebuilt gaming PC with Ryzen 5 9600X, RX 7600 and 16GB of RAM
MetaPCs launches first SteamOS 3 prebuilt gaming PC with Ryzen 5 9600X, RX 7600 and 16GB of RAM Profit is now PlayStation's #1 goal as it shifts away from pure MAU growth
Profit is now PlayStation's #1 goal as it shifts away from pure MAU growth RadeonTuner enables unofficial FSR 4 driver injection in games with RDNA 3.5 iGPUs
RadeonTuner enables unofficial FSR 4 driver injection in games with RDNA 3.5 iGPUs Sony deleting over 500 movies from PS5 libraries is a reminder that you don't really own anything in the digital age
Sony deleting over 500 movies from PS5 libraries is a reminder that you don't really own anything in the digital age Apple wants to buy memory from CXMT, a Chinese company that's currently blacklisted by the US government
Apple wants to buy memory from CXMT, a Chinese company that's currently blacklisted by the US government Analysts predict another massive memory price increase in Q3 2026, and another in Q4
Analysts predict another massive memory price increase in Q3 2026, and another in Q4 Sony President says live service games are still a big push for PlayStation's first-party studios
Sony President says live service games are still a big push for PlayStation's first-party studios Microsoft disputes claims that GTA 6 pre-orders on PS5 are out-selling Xbox 8-to-1
Microsoft disputes claims that GTA 6 pre-orders on PS5 are out-selling Xbox 8-to-1 Vanguard no longer has to run at startup thanks to Riot's new On-Demand mode
Vanguard no longer has to run at startup thanks to Riot's new On-Demand mode A new battery restoration method can bring lithium-ion batteries back to 95% of their original capacity
A new battery restoration method can bring lithium-ion batteries back to 95% of their original capacity GIGABYTE GO27Q24G Gaming Monitor Review: Glossy OLED Gaming at 240Hz
GIGABYTE GO27Q24G Gaming Monitor Review: Glossy OLED Gaming at 240Hz Lian Li B4-mATX Review: a compact mATX SFF case with excellent airflow and premium features
Lian Li B4-mATX Review: a compact mATX SFF case with excellent airflow and premium features MSI MPG 322UR QD-OLED X24 Review: A Brighter, Tougher 4K 240Hz QD-OLED for $1099
MSI MPG 322UR QD-OLED X24 Review: A Brighter, Tougher 4K 240Hz QD-OLED for $1099 UGREEN NASync DXP4800 GT Review: powerful 4-bay NAS with AMD Ryzen and dual 10GbE ports
UGREEN NASync DXP4800 GT Review: powerful 4-bay NAS with AMD Ryzen and dual 10GbE ports Dell XPS 14 (2026) Laptop Review - Premium Quality, Impressive Performance
Dell XPS 14 (2026) Laptop Review - Premium Quality, Impressive Performance Ocypus Sigma F36 BK ARGB Cooling Fan Review: high airflow and unified design in one frame
Ocypus Sigma F36 BK ARGB Cooling Fan Review: high airflow and unified design in one frame PCCooler CPS RZ820 Display Review: a flagship-level CPU air cooler with an LCD screen
PCCooler CPS RZ820 Display Review: a flagship-level CPU air cooler with an LCD screen Speed Racer (2008) 4K Ultra HD Blu-ray Review: a stunning remaster of the cult classic
Speed Racer (2008) 4K Ultra HD Blu-ray Review: a stunning remaster of the cult classic MOAIPLAY ORA PRO G1 850W ATX 3.1 PSU Review: high efficiency and 10-year warranty for $119.99
MOAIPLAY ORA PRO G1 850W ATX 3.1 PSU Review: high efficiency and 10-year warranty for $119.99 How to fix Wi-Fi Adapter Not Working on Windows laptops: troubleshooting tips
How to fix Wi-Fi Adapter Not Working on Windows laptops: troubleshooting tips Hisense U7SG 4K TV: Modern Entertainment for the New Age
Hisense U7SG 4K TV: Modern Entertainment for the New Age 6 underrated Microsoft Word features worth using to boost your productivity
6 underrated Microsoft Word features worth using to boost your productivity Level Up Your PC Gaming with these Fantastic ASUS Prime Day Deals on GPUs, Motherboards, and More
Level Up Your PC Gaming with these Fantastic ASUS Prime Day Deals on GPUs, Motherboards, and More GIGABYTE Wants to Kickstart Your New Gaming PC or Upgrade with These Limited-Time Deals
GIGABYTE Wants to Kickstart Your New Gaming PC or Upgrade with These Limited-Time Deals 7 Windows settings to change right after installation for better privacy, security, and performance
7 Windows settings to change right after installation for better privacy, security, and performance I stopped Windows 11 notifications from interrupting me with Do Not Disturb, Focus, and a priority list
I stopped Windows 11 notifications from interrupting me with Do Not Disturb, Focus, and a priority list I read the Windows Backup app screen carefully, and it does not back up what most people think
I read the Windows Backup app screen carefully, and it does not back up what most people think Low Sound Volume on Windows 11? How to fix audio issues and restore normal volume
Low Sound Volume on Windows 11? How to fix audio issues and restore normal volume