


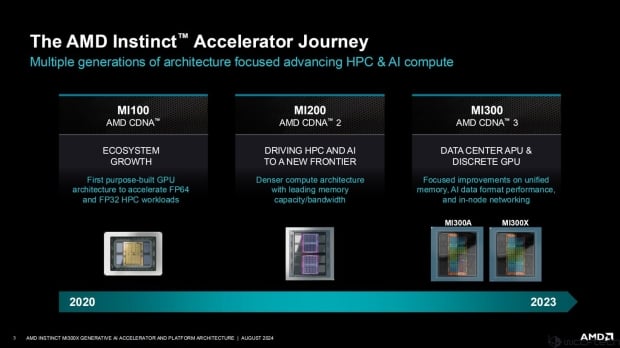

AMD's new Instinct MI300X AI accelerator with 192GB of HBM3E has had a deep dive at Hot Chips 2024 this week, as well as the company teasing its refreshed MI325X with 288GB of HBM3E later this year.

Inside, AMD's new Instinct MI300X AI Accelerator features a total of 153 billion transistors, using a mix of TSMC's new 5nm and 6nm FinFET process nodes. There are 8 chiplets that feature 4 shared engines, and each shared engine contains 10 compute units.
The entire chip packs 32 shader engines, with a total of 40 shader engines inside of a single XCD and 320 in total across the entire package. Each individual XCD has its dedicated L2 cache, and out the outskirts of the package, features the Infinity Fabric Link, 8 HBM3 IO sites, and a single PCIe Gen5 link with 128GB/sec of bandwidth that connects the MI300X to an AMD EPYC CPU.

AMD uses its in-house 4th Gen Infinity Fabric on its Insintct MI300X AI accelerator, with up to 896GB/sec of bandwidth. MI300X also uses Infinity Fabric Advanced Package link, connecting all of the chips with up to 4.8TB/sec of bisection bandwidth, while the XCD/IOD interface is at 2.TB/sec bandwidth.
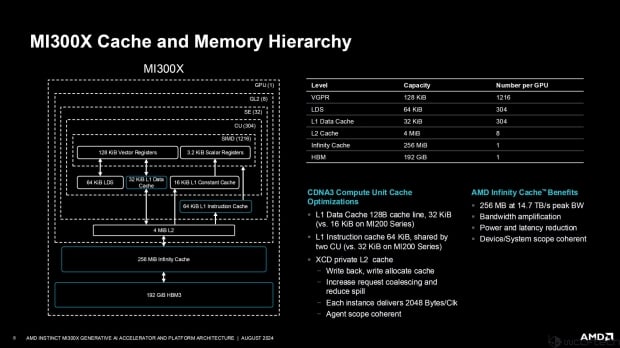
AMD provided a full block diagram of the MI300X architecture, with each XCD containing 2 compute units disabled, for a total of 304 CUs in MI300X out of the full 320 CU design. The full chip packs 20,480 cores while the MI300X has 19,456 cores. AMD also has 256MB of dedicated Infinity Cache on the MI300X, too.
The company also points out that its Instinct MI300X is the first AI accelerator to feature an 8-stack HBM3 memory design, with the 8-stack design allowing AMD to reach 1.5x higher capacity (128GB to 192GB) but also 1.6x higher memory bandwidth (3TB/sec to 5.2TB/sec) versus the MI250X.
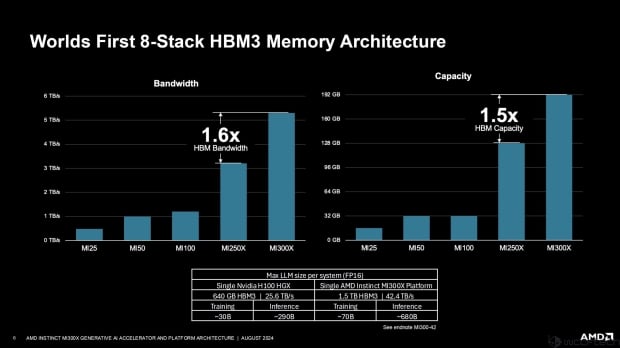
AMD says that with the larger and faster HBM memory, the new Instinct MI300X can handle larger LLMs (FP16) sizes of up to 70B in training, and 680B in inference. NVIDIA HGX H100 systems can only handle LLM models of up to 30B in training and up to 290B in inference.

One of the cool features of the Instinct MI300X is that AMD has its in-house Spatial portioning technology, allowing users to partition the XCDs depending on their workloads. Each of the XCDs operate together as a single processor, but they can be partioned and then grouped to appear as multiple GPUs.
AMD did tease its refreshed Instinct MI325X AI accelerator for October, which will pack HBM3E memory, and up to 288GB of it, with even higher speeds. AMD promises 1.3x more memory bandwidth, and 1.3x peak theoretical FP16 and FP8 compute performance improvements over the Instinct MI300X and its HBM3 memory.
In 2026 we'll be introduced to the next-gen Instinct MI400 series which is based on a future-gen CDNA architecture that the company has dubbed "CDNA Next".
The new AMD Instinct MI325X accelerator, which will bring 288GB of HBM3E memory and 6 terabytes per second of memory bandwidth, use the same industry standard Universal Baseboard server design used by the AMD Instinct MI300 series, and be generally available in Q4 2024. The accelerator will have industry leading memory capacity and bandwidth, 2x and 1.3x better than the competition respectively4, and 1.3x better5 compute performance than competition.
The first product in the AMD Instinct MI350 Series, the AMD Instinct MI350X accelerator, is based on the AMD CDNA 4 architecture and is expected to be available in 2025. It will use the same industry standard Universal Baseboard server design as other MI300 Series accelerators and will be built using advanced 3nm process technology, support the FP4 and FP6 AI datatypes and have up to 288 GB of HBM3E memory.
AMD CDNA "Next" architecture, which will power the AMD Instinct MI400 Series accelerators, is expected to be available in 2026 providing the latest features and capabilities that will help unlock additional performance and efficiency for inference and large-scale AI training.

 AMD announces 10.10 'Advancing AI 2024' event: EPYC Turin, Instinct MI325X, Ryzen AI 300 PRO
AMD announces 10.10 'Advancing AI 2024' event: EPYC Turin, Instinct MI325X, Ryzen AI 300 PRO TensorWave to build world's largest AMD GPU cluster in 2025 with MI300X, MI325X, MI350X AI GPUs
TensorWave to build world's largest AMD GPU cluster in 2025 with MI300X, MI325X, MI350X AI GPUs Microsoft lifts the lid on its new AI chip, Maia 100, up to 700W TDP, built for large-scale AI
Microsoft lifts the lid on its new AI chip, Maia 100, up to 700W TDP, built for large-scale AI AMD's new Instinct MI355X AI GPU has up to 288GB HBM3E memory, 1400W peak board power
AMD's new Instinct MI355X AI GPU has up to 288GB HBM3E memory, 1400W peak board power Pope's official prayer app exposed data of more than 700,000 users
Pope's official prayer app exposed data of more than 700,000 users Australian GTA Online players officially blocked by Rockstar from getting rarest vehicle
Australian GTA Online players officially blocked by Rockstar from getting rarest vehicle Wizards of the Coast president to leave position as Magic: The Gathering hits record $500M earnings
Wizards of the Coast president to leave position as Magic: The Gathering hits record $500M earnings NVIDIA GeForce driver 610.88 launches without a resolution for Battlefield 6 Season 4's crashing issues
NVIDIA GeForce driver 610.88 launches without a resolution for Battlefield 6 Season 4's crashing issues TCL debuts Ultimate Pro 32X3B and 27X3B gaming monitors with LG's 4th-gen WOLED panel
TCL debuts Ultimate Pro 32X3B and 27X3B gaming monitors with LG's 4th-gen WOLED panel Apple will offer the iPhone and Apple Watch for $17.99 and $11.99 per month
Apple will offer the iPhone and Apple Watch for $17.99 and $11.99 per month Memory supply could plummet 70% as AI's endless hunger devours global production
Memory supply could plummet 70% as AI's endless hunger devours global production Valve fixes Steam bug that downloaded games online instead of over your local network
Valve fixes Steam bug that downloaded games online instead of over your local network World's first tri-mode 1300Hz gaming monitor and 12K ultrawide confirmed
World's first tri-mode 1300Hz gaming monitor and 12K ultrawide confirmed MOZA's first full-cockpit HMA150 motion system adds a new dimension to flying or racing
MOZA's first full-cockpit HMA150 motion system adds a new dimension to flying or racing Logitech G316 X 98 Wired Gaming Keyboard Review - Retro-Inspired Board that Falls a Little Short
Logitech G316 X 98 Wired Gaming Keyboard Review - Retro-Inspired Board that Falls a Little Short Biwin M560 2TB SSD Review - Best Overall Retail-Ready DRAMless SSD
Biwin M560 2TB SSD Review - Best Overall Retail-Ready DRAMless SSD Logitech G512 X 98 Analog Mechanical Gaming Keyboard Review - An Innovative Two-in-One
Logitech G512 X 98 Analog Mechanical Gaming Keyboard Review - An Innovative Two-in-One Thrustmaster T.Flight HOTAS 5 MSFS Edition Review
Thrustmaster T.Flight HOTAS 5 MSFS Edition Review SteelSeries Arctis Nova Pro Omni Wireless Headset Review - One Headset to Rule Them All
SteelSeries Arctis Nova Pro Omni Wireless Headset Review - One Headset to Rule Them All SteelSeries Arctis Nova 7 Wireless Gen 2 Headset Review - New and Improved, But Is It Enough?
SteelSeries Arctis Nova 7 Wireless Gen 2 Headset Review - New and Improved, But Is It Enough? AMD Ryzen 7 7700X3D Review - Days of Future Past
AMD Ryzen 7 7700X3D Review - Days of Future Past Samsung 990 2TB SSD Review - Ninth Gen QLC at PCIe Gen4 Speeds
Samsung 990 2TB SSD Review - Ninth Gen QLC at PCIe Gen4 Speeds ASUS ExpertBook Ultra (Panther Lake) 14" Business Laptop Review
ASUS ExpertBook Ultra (Panther Lake) 14" Business Laptop Review ASUS ROG Raikiri II Xbox Wireless Controller Review - Ready to Take Control
ASUS ROG Raikiri II Xbox Wireless Controller Review - Ready to Take Control Printer Not Working in Windows? How to fix detection, print queues and drivers
Printer Not Working in Windows? How to fix detection, print queues and drivers The Ultimate Guide to Personalizing Your Windows 11 Taskbar
The Ultimate Guide to Personalizing Your Windows 11 Taskbar How to Turn Your Windows Laptop Into a Second Monitor with Miracast and Wireless Display in Minutes
How to Turn Your Windows Laptop Into a Second Monitor with Miracast and Wireless Display in Minutes 6 Mistakes to Avoid When Buying a Windows Laptop
6 Mistakes to Avoid When Buying a Windows Laptop I capped Windows Update's bandwidth with Delivery Optimization, and my downloads stopped choking
I capped Windows Update's bandwidth with Delivery Optimization, and my downloads stopped choking I use this decade-old free tool that finds files faster than Windows Search does
I use this decade-old free tool that finds files faster than Windows Search does I install and update most of my apps with this Windows command now, and I stopped downloading sketchy installers
I install and update most of my apps with this Windows command now, and I stopped downloading sketchy installers Hisense U6SF 65-inch MiniLED TV: High Performance Meets Leisurely Convenience
Hisense U6SF 65-inch MiniLED TV: High Performance Meets Leisurely Convenience I stopped digging through Windows menus after I set up this one folder
I stopped digging through Windows menus after I set up this one folder Don't sell your Windows laptop until you do these things
Don't sell your Windows laptop until you do these things