




A new artificial intelligence system developed by Microsoft is slated to have the capability of cloning anyone's voice by just listening to a three-second audio example.
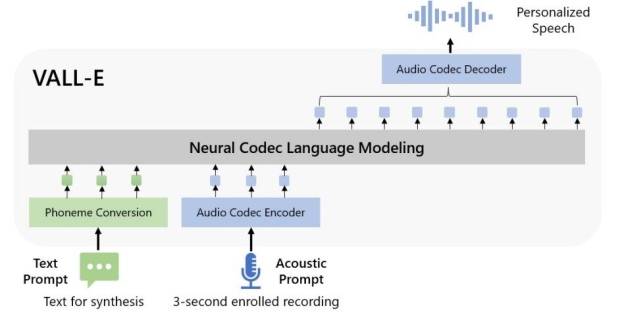
The new AI is called VALL-E, and according to a newly released paper, the system is a neural codec language model that is a text-to-speech synthesizer. According to the report, VALL-E is capable of learning a specific voice and then synthesizing it to be able to say whatever is desired. Additionally, the report claims that VALL-E will be able to produce a voice identical to the example it was given while also retaining the same or a similar level of emotional tone that is heard in speech - something other AI synthesizers struggle to do successfully.
The creators of the AI system believe it will be used to power text-to-speech applications, speech editing, and audio content creation when combined with other generative language models, such as Open AI's immensely popular ChapGPT. Notably, the creators believe that VALL-E would be used for speech editing that would include taking a three-second audio example of an individual's voice and making them say something they didn't. Listen to examples of VALL-E here.
"We introduce a language modeling approach for text to speech synthesis (TTS). Specifically, we train a neural codec language model (called VALL-E) using discrete codes derived from an off-the-shelf neural audio codec model, and regard TTS as a conditional language modeling task rather than continuous signal regression as in previous work.
During the pre-training stage, we scale up the TTS training data to 60K hours of English speech, which is hundreds of times larger than existing systems. VALL-E emerges in-context learning capabilities and can be used to synthesize high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt.
Experiment results show that VALL-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. In addition, we find VALL-E could preserve the speaker's emotion and acoustic environment of the acoustic prompt in synthesis," the report states.

 Microsoft made an AI human voice generator so dangerous it couldn't be released
Microsoft made an AI human voice generator so dangerous it couldn't be released US secretary of state impersonated by AI: foreign ministers and Congress members contacted
US secretary of state impersonated by AI: foreign ministers and Congress members contacted Black Ops 6 is shaping up to be the least toxic Call of Duty game ever
Black Ops 6 is shaping up to be the least toxic Call of Duty game ever Siri overhaul revealed: Apple to let users pick their own AI assistant inside iOS 27
Siri overhaul revealed: Apple to let users pick their own AI assistant inside iOS 27 Elon Musk's SpaceX showcases Grok-powered smartphone built to reshape AI interaction
Elon Musk's SpaceX showcases Grok-powered smartphone built to reshape AI interaction Sony declares AI as core part of future game development at PlayStation
Sony declares AI as core part of future game development at PlayStation Security researchers trick AI browsers into revealing passwords using BioShock-inspired prompt injection
Security researchers trick AI browsers into revealing passwords using BioShock-inspired prompt injection Cyberpunk 2077 sells over 40 million copies, 10 million more than The Witcher 3 in the same time
Cyberpunk 2077 sells over 40 million copies, 10 million more than The Witcher 3 in the same time PlayStation games out before 2028 can still get disc reprints
PlayStation games out before 2028 can still get disc reprints Nintendo may raise Switch 2 prices a second time, company plotting Fiscal Year 2028 with assumption that costs will rise
Nintendo may raise Switch 2 prices a second time, company plotting Fiscal Year 2028 with assumption that costs will rise Sony limiting PS5 disc drives to 1 per person following decision to kill PlayStation physical media
Sony limiting PS5 disc drives to 1 per person following decision to kill PlayStation physical media Intel confirms new price hike for Core Ultra 200S Plus CPUs, blames rising supply chain costs
Intel confirms new price hike for Core Ultra 200S Plus CPUs, blames rising supply chain costs Microsoft fires shots at Sony over PlayStation disc phase out by offering free CDs through GitHub
Microsoft fires shots at Sony over PlayStation disc phase out by offering free CDs through GitHub Sony stock up 7% following decision to terminate game disc production
Sony stock up 7% following decision to terminate game disc production KTC H49S66 5K2K (5120x1440) 49-inch 180Hz Gaming Monitor Review
KTC H49S66 5K2K (5120x1440) 49-inch 180Hz Gaming Monitor Review HighPoint Rocket 1604L Gen5 x16 NVMe SoftRAID AIC Review: half the price with full 59 GB/s speed
HighPoint Rocket 1604L Gen5 x16 NVMe SoftRAID AIC Review: half the price with full 59 GB/s speed Next Level Racing ERS3 Haptic Seat Review: immersive sim racing comfort with integrated haptics
Next Level Racing ERS3 Haptic Seat Review: immersive sim racing comfort with integrated haptics ASUS TUF Gaming X870-Pro WiFi7 W NEO Review - Tuffed up
ASUS TUF Gaming X870-Pro WiFi7 W NEO Review - Tuffed up GIGABYTE GO27Q24G Gaming Monitor Review: Glossy OLED Gaming at 240Hz
GIGABYTE GO27Q24G Gaming Monitor Review: Glossy OLED Gaming at 240Hz Lian Li B4-mATX Review: a compact mATX SFF case with excellent airflow and premium features
Lian Li B4-mATX Review: a compact mATX SFF case with excellent airflow and premium features MSI MPG 322UR QD-OLED X24 Review: A Brighter, Tougher 4K 240Hz QD-OLED for $1099
MSI MPG 322UR QD-OLED X24 Review: A Brighter, Tougher 4K 240Hz QD-OLED for $1099 UGREEN NASync DXP4800 GT Review: powerful 4-bay NAS with AMD Ryzen and dual 10GbE ports
UGREEN NASync DXP4800 GT Review: powerful 4-bay NAS with AMD Ryzen and dual 10GbE ports Dell XPS 14 (2026) Laptop Review - Premium Quality, Impressive Performance
Dell XPS 14 (2026) Laptop Review - Premium Quality, Impressive Performance Ocypus Sigma F36 BK ARGB Cooling Fan Review: high airflow and unified design in one frame
Ocypus Sigma F36 BK ARGB Cooling Fan Review: high airflow and unified design in one frame 7 tips to organize your Windows files for faster, easier access
7 tips to organize your Windows files for faster, easier access Intel Arc G3 Extreme first impressions with MSI's Claw 8 EX AI+ - Incredible power for an extreme price
Intel Arc G3 Extreme first impressions with MSI's Claw 8 EX AI+ - Incredible power for an extreme price How to fix Wi-Fi Adapter Not Working on Windows laptops: troubleshooting tips
How to fix Wi-Fi Adapter Not Working on Windows laptops: troubleshooting tips Hisense U7SG 4K TV: Modern Entertainment for the New Age
Hisense U7SG 4K TV: Modern Entertainment for the New Age 6 underrated Microsoft Word features worth using to boost your productivity
6 underrated Microsoft Word features worth using to boost your productivity Level Up Your PC Gaming with these Fantastic ASUS Prime Day Deals on GPUs, Motherboards, and More
Level Up Your PC Gaming with these Fantastic ASUS Prime Day Deals on GPUs, Motherboards, and More GIGABYTE Wants to Kickstart Your New Gaming PC or Upgrade with These Limited-Time Deals
GIGABYTE Wants to Kickstart Your New Gaming PC or Upgrade with These Limited-Time Deals 7 Windows settings to change right after installation for better privacy, security, and performance
7 Windows settings to change right after installation for better privacy, security, and performance I stopped Windows 11 notifications from interrupting me with Do Not Disturb, Focus, and a priority list
I stopped Windows 11 notifications from interrupting me with Do Not Disturb, Focus, and a priority list