




The underlying technology of all of these AI-powered tools that are continuous popping up in various sectors of the technology industry are Large Language Models (LLMs), which are powered by number-crunching graphics cards, or GPUs.
The explosion of AI has been fuelled by the possibility of graphics cards now being powerful enough to crunch large swaths of data into a model that can then be queried by users. However, powerful models such as ChatGPT, require thousands of GPUs to continuously fulfil all the requests of the millions of users enjoying the service.
But what if you just wanted to support a few thousand users at a time? Perhaps you are a business that could need an AI chatbot to assist with customer service via your website? And ultimately, do you need thousands of GPUs to achieve this? Apparently not, or at least according to benchmarks from Backprop, an Estonian GPU cloud start-up who managed to get a modest LLM such as Llama 3.1 8B to work on a single NVIDIA RTX 3090 GPU, which was released in late 2020.
- Read more: Phison's world-first 6nm AI computing SSD solution wins Best Choice Golden Award at Computex
- Read more: Microsoft Azure upgraded to NVIDIA GB300 'Blackwell Ultra' with 4600 GPUs connected together
- Read more: AMD's new Ryzen AI Max+ 395 'Strix Halo' APU is 3x faster in DeepSeek R1 AI bench than RTX 5080
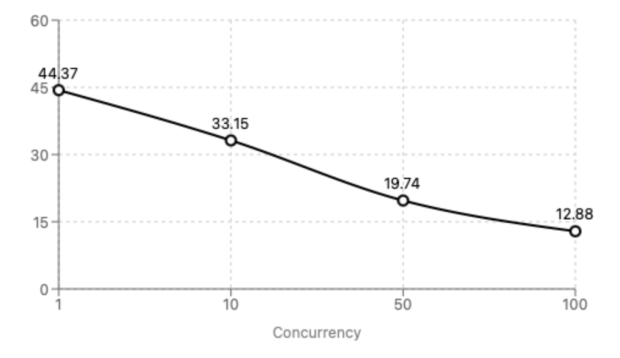
The start-up found throughout its testing the RTX 3090 provided AI performance that was comparable to a customer service AI chatbot, with the GPU from 2020 only being able to fulfil requests from 100 concurrent users. In a test the RTX 3090 was able to serve a user 12.88 tokens per second, which is faster than the average person can read at five works per second, and faster than the industry standard for an AI chatbot, which is 10 tokens per second.
It appears its possible to run a customer service-equivalent AI chatbot with a single RTX 3090 GPU, and this AI chatbot could support thousands of users and fulfil the requests of 100s at any given time.

 Phison partners with Maingear for world's 1st laptop built for fine-tune AI training
Phison partners with Maingear for world's 1st laptop built for fine-tune AI training NVIDIA's RTX Spark Superchip brings 120B-parameter local AI agents to Windows PCs
NVIDIA's RTX Spark Superchip brings 120B-parameter local AI agents to Windows PCs Phison's world-first 6nm AI computing SSD solution wins Best Choice Golden Award at Computex
Phison's world-first 6nm AI computing SSD solution wins Best Choice Golden Award at Computex Acer's new Veriton GN100: AI Mini-PC powered by the new NVIDIA GB10 Superchip, starts at $3999
Acer's new Veriton GN100: AI Mini-PC powered by the new NVIDIA GB10 Superchip, starts at $3999 NVIDIA announces RTX Spark, a Windows on Arm superchip for laptops and compact PCs
NVIDIA announces RTX Spark, a Windows on Arm superchip for laptops and compact PCs Intel and AMD are locking Chinese customers into long-term CPU deals as server chip prices climb more than 40%
Intel and AMD are locking Chinese customers into long-term CPU deals as server chip prices climb more than 40% Ubisoft CEO says Sony's PlayStation disc shutdown will not disturb the industry too much
Ubisoft CEO says Sony's PlayStation disc shutdown will not disturb the industry too much Vibe coding is flooding the App Store with new apps - on track for record submissions in 2026
Vibe coding is flooding the App Store with new apps - on track for record submissions in 2026 Geekbench 7 is out with CUDA support, smarter multi-core scoring, and new AI workloads across all major platforms
Geekbench 7 is out with CUDA support, smarter multi-core scoring, and new AI workloads across all major platforms GTA 6 physical copies in Japan have a 170-day expiration date
GTA 6 physical copies in Japan have a 170-day expiration date Ubisoft believes remakes can be more profitable than new releases, after Black Flag Resynced exceeds expectations
Ubisoft believes remakes can be more profitable than new releases, after Black Flag Resynced exceeds expectations AMD is preparing the 8-core Ryzen 7 9800HX3D CPU for laptops with 96MB L3 cache
AMD is preparing the 8-core Ryzen 7 9800HX3D CPU for laptops with 96MB L3 cache Blizzard fires World of Warcraft game master for abusing god-like powers
Blizzard fires World of Warcraft game master for abusing god-like powers GIGABYTE adds CXMT DDR5 support to AM5 motherboards, supporting speeds up to 8200 MT/s
GIGABYTE adds CXMT DDR5 support to AM5 motherboards, supporting speeds up to 8200 MT/s Xbox 360 tech powers backwards compatibility on PC, original Xbox games use Xefu emulation
Xbox 360 tech powers backwards compatibility on PC, original Xbox games use Xefu emulation Thrustmaster T.Flight HOTAS 5 MSFS Edition Review
Thrustmaster T.Flight HOTAS 5 MSFS Edition Review SteelSeries Arctis Nova Pro Omni Wireless Headset Review - One Headset to Rule Them All
SteelSeries Arctis Nova Pro Omni Wireless Headset Review - One Headset to Rule Them All SteelSeries Arctis Nova 7 Wireless Gen 2 Headset Review - New and Improved, But Is It Enough?
SteelSeries Arctis Nova 7 Wireless Gen 2 Headset Review - New and Improved, But Is It Enough? AMD Ryzen 7 7700X3D Review - Days of Future Past
AMD Ryzen 7 7700X3D Review - Days of Future Past Samsung 990 2TB SSD Review - Ninth Gen QLC at PCIe Gen4 Speeds
Samsung 990 2TB SSD Review - Ninth Gen QLC at PCIe Gen4 Speeds ASUS ExpertBook Ultra (Panther Lake) 14" Business Laptop Review
ASUS ExpertBook Ultra (Panther Lake) 14" Business Laptop Review ASUS ROG Raikiri II Xbox Wireless Controller Review - Ready to Take Control
ASUS ROG Raikiri II Xbox Wireless Controller Review - Ready to Take Control MOZA FMP18 Panel Bundle Review: authentic F/A-18 Hornet cockpit controls for flight sims
MOZA FMP18 Panel Bundle Review: authentic F/A-18 Hornet cockpit controls for flight sims Micron 6600 ION 245.76TB Enterprise SSD Review - Best in Class Programming Speeds
Micron 6600 ION 245.76TB Enterprise SSD Review - Best in Class Programming Speeds MOZA MA3F EFCM Flight Control Module Review: authentic Airbus A320 autopilot panel for simulators
MOZA MA3F EFCM Flight Control Module Review: authentic Airbus A320 autopilot panel for simulators How to Turn Your Windows Laptop Into a Second Monitor with Miracast and Wireless Display in Minutes
How to Turn Your Windows Laptop Into a Second Monitor with Miracast and Wireless Display in Minutes 6 Mistakes to Avoid When Buying a Windows Laptop
6 Mistakes to Avoid When Buying a Windows Laptop I capped Windows Update's bandwidth with Delivery Optimization, and my downloads stopped choking
I capped Windows Update's bandwidth with Delivery Optimization, and my downloads stopped choking I use this decade-old free tool that finds files faster than Windows Search does
I use this decade-old free tool that finds files faster than Windows Search does I install and update most of my apps with this Windows command now, and I stopped downloading sketchy installers
I install and update most of my apps with this Windows command now, and I stopped downloading sketchy installers Hisense U6SF 65-inch MiniLED TV: High Performance Meets Leisurely Convenience
Hisense U6SF 65-inch MiniLED TV: High Performance Meets Leisurely Convenience I stopped digging through Windows menus after I set up this one folder
I stopped digging through Windows menus after I set up this one folder Don't sell your Windows laptop until you do these things
Don't sell your Windows laptop until you do these things 6 PC cleaning mistakes to avoid for safer hardware maintenance
6 PC cleaning mistakes to avoid for safer hardware maintenance Phison and Intel Take Aim at Local AI's Memory Wall with aiDAPTIV
Phison and Intel Take Aim at Local AI's Memory Wall with aiDAPTIV