




AMD launched its new flagship AI GPU and accelerator, the Instinct MI300X, earlier this month. During the launch event, AMD provided charts and data indicating that the MI300X outperformed NVIDIA's powerful H100 GPU in several tests.

It was up to 60% faster in a direct 8 to 8 server comparison; however, NVIDIA followed up with its own data. NVDIA's report shows (with data) that AMD did not use the latest NVIDIA TensorRT-LLM kernel optimizations for NVIDIA Hopper, nor did it show real-world MLPerf server scenarios where DGX H100 hardware delivers impressive "inferences per second" results.
Long story short, NVIDIA's response claims that if AMD benchmarked the H100 GPU properly, it would show that Team Green's flagship was 2X faster. So, where does that bring us to? AMD has reached out with an update showing that the MI300X's performance advantage has increased thanks to its own optimizations. And it's now accounting for latency.
In a new blog post titled "Competitive performance claims and industry-leading Inference performance on AMD Instinct MI300X," AMD confirms that it did not use TensorRT-LLM optimizations in its original benchmarks because the data was recorded in November, before the update.
"We are at a stage in our product ramp where we are consistently identifying new paths to unlock performance with our ROCM software and AMD Instinct MI300 accelerators," AMD writes. "The data that was presented in our launch event was recorded in November. We have made a lot of progress since we recorded data in November that we used at our launch event and are delighted to share our latest results highlighting these gains."
This is where it all gets a little technical, but AMD's new results show that its "performance advantage has increased to 2.1X" in favor of the MI300X using AMD's new-found optimizations. However, throw in NVIDIA's optimized TensorRT-LLM, and that figure drops to 1.3X - still favoring the MI300X.
Here are AMD's latest results.
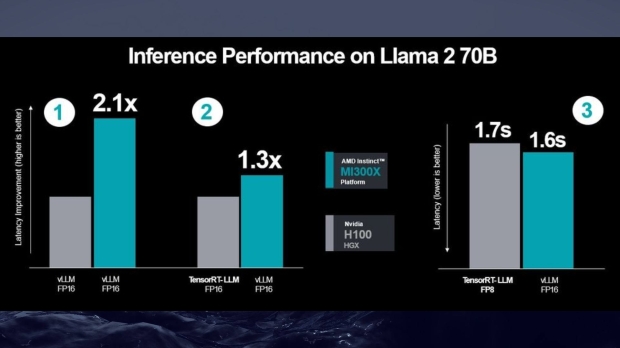
- MI300X to H100 using vLLM for both.
- MI300X using vLLM vs H100 using NVIDIA's optimized TensorRT-LLM
- Measured latency results for MI300X FP16 dataset vs H100 using TensorRT-LLM and FP8 dataset
AMD states that NVIDIA's benchmarks compared "FP16 datatype on AMD Instinct MI300X GPUs to FP8 datatype on H100," while its new results compare FP16 and FP16. "MI300X continues to demonstrate a performance advantage when measuring absolute latency," AMD adds. "Even when using lower precisions FP8 and TensorRT-LLM for H100 vs. vLLM and the higher precision FP16 datatype for MI300X."
FP8 only works with TensorRT-LLM. So what's the takeaway? AI hardware, benchmarks, and optimizations are happening very fast, and with various tests and scenarios, both AMD's MI300X and NVIDIA's H100 are powerful bits of hardware. However, these new results from AMD do show the MI300X has the advantage in these specific tests.
We've reached out to NVIDIA for a statement on AMD's latest results.

 NVIDIA shows off its beefed-up H200 AI GPU beating AMD's just-released Instinct MI300X
NVIDIA shows off its beefed-up H200 AI GPU beating AMD's just-released Instinct MI300X AMD details Instinct MI300X MCM GPU: 192GB of HBM3 out now, MI325X with 288GB HBM3E in October
AMD details Instinct MI300X MCM GPU: 192GB of HBM3 out now, MI325X with 288GB HBM3E in October Microsoft lifts the lid on its new AI chip, Maia 100, up to 700W TDP, built for large-scale AI
Microsoft lifts the lid on its new AI chip, Maia 100, up to 700W TDP, built for large-scale AI Dell PowerEdge XE9712: NVIDIA GB200 NVL72-based AI GPU cluster for LLM training, inference
Dell PowerEdge XE9712: NVIDIA GB200 NVL72-based AI GPU cluster for LLM training, inference AMD acquires server builder ZT Systems for $4.9 billion, will fight NVIDIA's AI infrastructure
AMD acquires server builder ZT Systems for $4.9 billion, will fight NVIDIA's AI infrastructure A trip down memory lane: A visit to Lexar's impressive memory museum in Zhongshan, China
A trip down memory lane: A visit to Lexar's impressive memory museum in Zhongshan, China Diablo 4 Season 14 changes how the best items in the game work
Diablo 4 Season 14 changes how the best items in the game work AMD updates FSR SDK with FSR 4.1.1 support for RDNA 3 and improved FSR Ray Regeneration 1.2.0
AMD updates FSR SDK with FSR 4.1.1 support for RDNA 3 and improved FSR Ray Regeneration 1.2.0 Valve offers update on Steam Deck 2, says it's close but still has one issue to solve
Valve offers update on Steam Deck 2, says it's close but still has one issue to solve Creative's new compact XF1 desktop PC speakers support Hi-Res audio
Creative's new compact XF1 desktop PC speakers support Hi-Res audio 8BitDo unveils new Nintendo 64-inspired Retro 87 Keyboard
8BitDo unveils new Nintendo 64-inspired Retro 87 Keyboard OLED buyer becomes victim of Amazon scam, receives broken 240Hz OLED screen instead of 540Hz OLED they initially ordered
OLED buyer becomes victim of Amazon scam, receives broken 240Hz OLED screen instead of 540Hz OLED they initially ordered Google taps MediaTek to build its next Triggerfish TPU chip launching in 2027
Google taps MediaTek to build its next Triggerfish TPU chip launching in 2027 Samsung announces world's first UFS 5.0 chip with 10.8 GB/s read and 9.5 GB/s write speeds
Samsung announces world's first UFS 5.0 chip with 10.8 GB/s read and 9.5 GB/s write speeds GTA 6 will feature a story chapter system like Red Dead Redemption 2
GTA 6 will feature a story chapter system like Red Dead Redemption 2 UGREEN NASync DXP4800 GT Review: powerful 4-bay NAS with AMD Ryzen and dual 10GbE ports
UGREEN NASync DXP4800 GT Review: powerful 4-bay NAS with AMD Ryzen and dual 10GbE ports Dell XPS 14 (2026) Laptop Review - Premium Quality, Impressive Performance
Dell XPS 14 (2026) Laptop Review - Premium Quality, Impressive Performance Ocypus Sigma F36 BK ARGB Cooling Fan Review: high airflow and unified design in one frame
Ocypus Sigma F36 BK ARGB Cooling Fan Review: high airflow and unified design in one frame PCCooler CPS RZ820 Display Review: a flagship-level CPU air cooler with an LCD screen
PCCooler CPS RZ820 Display Review: a flagship-level CPU air cooler with an LCD screen Speed Racer (2008) 4K Ultra HD Blu-ray Review: a stunning remaster of the cult classic
Speed Racer (2008) 4K Ultra HD Blu-ray Review: a stunning remaster of the cult classic MOAIPLAY ORA PRO G1 850W ATX 3.1 PSU Review: high efficiency and 10-year warranty for $119.99
MOAIPLAY ORA PRO G1 850W ATX 3.1 PSU Review: high efficiency and 10-year warranty for $119.99 Navman MiVue Smart True 4K Surround Dashcam Review - Seeing In All Directions At Once
Navman MiVue Smart True 4K Surround Dashcam Review - Seeing In All Directions At Once IQUNIX Magi96 Pro Aluminum Low Profile Mechanical Keyboard Review - Premium Build, Satisfying Sound
IQUNIX Magi96 Pro Aluminum Low Profile Mechanical Keyboard Review - Premium Build, Satisfying Sound Asetek Forte S-Series Racing Simulator Bundle Review
Asetek Forte S-Series Racing Simulator Bundle Review Level Up Your PC Gaming with these Fantastic ASUS Prime Day Deals on GPUs, Motherboards, and More
Level Up Your PC Gaming with these Fantastic ASUS Prime Day Deals on GPUs, Motherboards, and More GIGABYTE Wants to Kickstart Your New Gaming PC or Upgrade with These Limited-Time Deals
GIGABYTE Wants to Kickstart Your New Gaming PC or Upgrade with These Limited-Time Deals 7 Windows settings to change right after installation for better privacy, security, and performance
7 Windows settings to change right after installation for better privacy, security, and performance I stopped Windows 11 notifications from interrupting me with Do Not Disturb, Focus, and a priority list
I stopped Windows 11 notifications from interrupting me with Do Not Disturb, Focus, and a priority list I read the Windows Backup app screen carefully, and it does not back up what most people think
I read the Windows Backup app screen carefully, and it does not back up what most people think Low Sound Volume on Windows 11? How to fix audio issues and restore normal volume
Low Sound Volume on Windows 11? How to fix audio issues and restore normal volume 8 Critical Warning Signs You Should Never Ignore in Windows 11
8 Critical Warning Signs You Should Never Ignore in Windows 11 This Windows security feature protects Documents from ransomware, but it is off by default
This Windows security feature protects Documents from ransomware, but it is off by default Windows 11 already has a voice typing tool, and it is the one most people are not using
Windows 11 already has a voice typing tool, and it is the one most people are not using