




[UPDATE AMD has responded to the below with updated benchmark results and new optimizations of its own to show that the MI300X still has the performance advantage - read all about it here]. AMD, like all of the big players in the chip game, is going all in on AI hardware, and with the company's recent flagship MI300X GPU launch, it made some bold claims that compared performance between the MI300X and NVIDIA's powerful H100 GPU. Up to 20% faster than the H100 in a direct 1 to 1 comparison and up to 60% faster in an 8 to 8 server comparison.
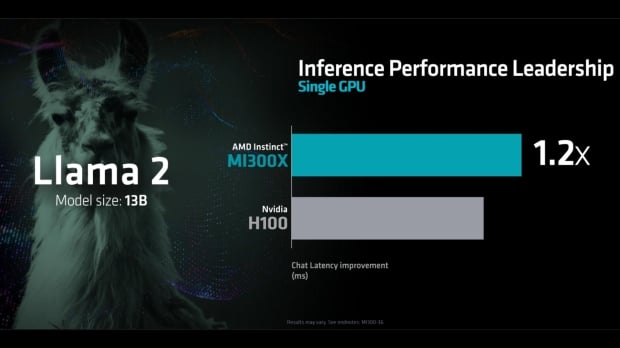
Every slide in AMD's 'Advancing AI' presentation that covered the performance of the AMD Instinct MI300X to the NVIDIA H100 Tensor Core GPU shows the MI300X coming out on top or, at worse, performing on par. And with that, NVIDIA has taken the time to present its own results showing that the H100 GPU is 2X faster than the MI300X.
"At a recent launch event, AMD talked about the inference performance of the H100 GPU compared to that of its MI300X chip," NVIDIA's Dave Salvator and Ashraf Eassa write. "The results shared did not use optimized software, and the H100, if benchmarked properly, is 2X faster."
- Read more: AMD Instinct MI455X GPU launches with 432GB of HBM4 memory and next-gen CDNA 5 architecture
- Read more: Phison's world-first 6nm AI computing SSD solution wins Best Choice Golden Award at Computex
- Read more: Bolt Graphics Zeus GPU: up to 10x faster than RTX 5090 in rendering workloads, expandable RAM
Benchmarking "properly" means using NVIDIA's latest NVIDIA TensorRT-LLM kernel optimizations for the NVIDIA Hopper architecture, which significantly alters the results displayed by AMD during its presentation.
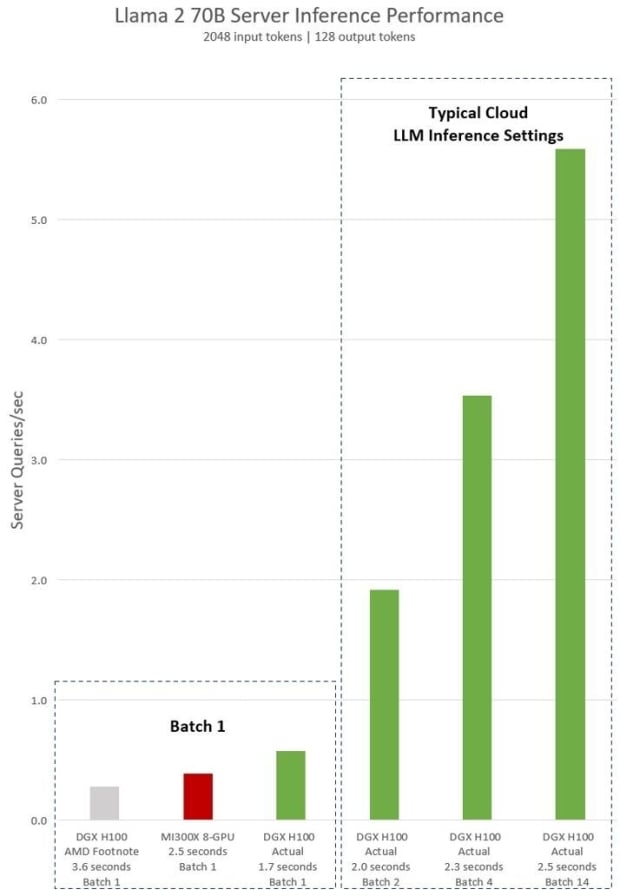
Llama 2 70B, a model used in AMD's presentation, is greatly accelerated. There's no shade or tone to NVIDIA's response, an article with the title 'Achieving Top Inference Performance with the NVIDIA H100 Tensor Core GPU and NVIDIA TensorRT-LLM.' The chart above shows "Llama 2 70B server inference performance in queries per second with 2,048 input tokens and 128 output tokens for "Batch 1" and various fixed response time settings," with a clear victory for the H100 GPU.
It also includes typical cloud settings for AI where inference requests are handled in larger batches - an industry standard. AMD didn't include results for MI300X for this particular real-world use case, so NVIDIA has, showcasing that the "8-GPU DGX H100 server can process over five Llama 2 70B inferences per second." Naturally, NVIDIA didn't put the MI300X to the test here - making the H100's performance look even more impressive.
NVIDIA's response does imply that not using the "publicly available NVIDIA TensorRT-LLM" update was a deliberate move on AMD's part. To make its flagship AI GPU, the MI300X look better than it is? Possibly.
Either way, this is one of those mess-around and find-out situations for using cherry-picked benchmarks in a presentation.

 AMD details Instinct MI300X MCM GPU: 192GB of HBM3 out now, MI325X with 288GB HBM3E in October
AMD details Instinct MI300X MCM GPU: 192GB of HBM3 out now, MI325X with 288GB HBM3E in October Microsoft lifts the lid on its new AI chip, Maia 100, up to 700W TDP, built for large-scale AI
Microsoft lifts the lid on its new AI chip, Maia 100, up to 700W TDP, built for large-scale AI NVIDIA shows off its beefed-up H200 AI GPU beating AMD's just-released Instinct MI300X
NVIDIA shows off its beefed-up H200 AI GPU beating AMD's just-released Instinct MI300X TensorWave to build world's largest AMD GPU cluster in 2025 with MI300X, MI325X, MI350X AI GPUs
TensorWave to build world's largest AMD GPU cluster in 2025 with MI300X, MI325X, MI350X AI GPUs AMD acquires server builder ZT Systems for $4.9 billion, will fight NVIDIA's AI infrastructure
AMD acquires server builder ZT Systems for $4.9 billion, will fight NVIDIA's AI infrastructure GeForce RTX 50 Series GPU prices are rumored to increase by 30% in the coming weeks, months
GeForce RTX 50 Series GPU prices are rumored to increase by 30% in the coming weeks, months TSMC's 1.4nm process timeline accelerates, with mass production happening sooner than expected
TSMC's 1.4nm process timeline accelerates, with mass production happening sooner than expected Diablo 4's next season is bringing back iconic items from Diablo 2 and 3
Diablo 4's next season is bringing back iconic items from Diablo 2 and 3 Razer Huntsman V3 HE Magnetic 8K keyboards include a Mini 65% model
Razer Huntsman V3 HE Magnetic 8K keyboards include a Mini 65% model Four C's of Xbox's future outlined in new CEO memo
Four C's of Xbox's future outlined in new CEO memo Linux kernel patch boosts Steam Deck 1% lows by 31.8% by fixing AMD CPU clock handling
Linux kernel patch boosts Steam Deck 1% lows by 31.8% by fixing AMD CPU clock handling Nexus Mods new owner wants to make installing mods as easy as using Spotify
Nexus Mods new owner wants to make installing mods as easy as using Spotify Dragon Age remasters are technically possible but won't be easy, BioWare co-founder says
Dragon Age remasters are technically possible but won't be easy, BioWare co-founder says The EU is preparing to hit ChatGPT and Roblox with its strictest content moderation rules
The EU is preparing to hit ChatGPT and Roblox with its strictest content moderation rules Man outsmarts GPU scammers by filming his RTX 5070 Ti unboxing, and finds two-liter water bottle inside
Man outsmarts GPU scammers by filming his RTX 5070 Ti unboxing, and finds two-liter water bottle inside ASUS ROG Strix X870E-A Gaming WiFI7 Neo Review - A New Enticing Option
ASUS ROG Strix X870E-A Gaming WiFI7 Neo Review - A New Enticing Option Noctua NL-LC1-36 Liquid CPU Cooler Review
Noctua NL-LC1-36 Liquid CPU Cooler Review Logitech G316 X 98 Wired Gaming Keyboard Review - Retro-Inspired Board that Falls a Little Short
Logitech G316 X 98 Wired Gaming Keyboard Review - Retro-Inspired Board that Falls a Little Short Biwin M560 2TB SSD Review - Best Overall Retail-Ready DRAMless SSD
Biwin M560 2TB SSD Review - Best Overall Retail-Ready DRAMless SSD Logitech G512 X 98 Analog Mechanical Gaming Keyboard Review - An Innovative Two-in-One
Logitech G512 X 98 Analog Mechanical Gaming Keyboard Review - An Innovative Two-in-One Thrustmaster T.Flight HOTAS 5 MSFS Edition Review
Thrustmaster T.Flight HOTAS 5 MSFS Edition Review SteelSeries Arctis Nova Pro Omni Wireless Headset Review - One Headset to Rule Them All
SteelSeries Arctis Nova Pro Omni Wireless Headset Review - One Headset to Rule Them All SteelSeries Arctis Nova 7 Wireless Gen 2 Headset Review - New and Improved, But Is It Enough?
SteelSeries Arctis Nova 7 Wireless Gen 2 Headset Review - New and Improved, But Is It Enough? AMD Ryzen 7 7700X3D Review - Days of Future Past
AMD Ryzen 7 7700X3D Review - Days of Future Past Samsung 990 2TB SSD Review - Ninth Gen QLC at PCIe Gen4 Speeds
Samsung 990 2TB SSD Review - Ninth Gen QLC at PCIe Gen4 Speeds I switched my PC to encrypted DNS in Windows 11, and browsing felt more private
I switched my PC to encrypted DNS in Windows 11, and browsing felt more private Printer Not Working in Windows? How to fix detection, print queues and drivers
Printer Not Working in Windows? How to fix detection, print queues and drivers The Ultimate Guide to Personalizing Your Windows 11 Taskbar
The Ultimate Guide to Personalizing Your Windows 11 Taskbar How to Turn Your Windows Laptop Into a Second Monitor with Miracast and Wireless Display in Minutes
How to Turn Your Windows Laptop Into a Second Monitor with Miracast and Wireless Display in Minutes 6 Mistakes to Avoid When Buying a Windows Laptop
6 Mistakes to Avoid When Buying a Windows Laptop I capped Windows Update's bandwidth with Delivery Optimization, and my downloads stopped choking
I capped Windows Update's bandwidth with Delivery Optimization, and my downloads stopped choking I use this decade-old free tool that finds files faster than Windows Search does
I use this decade-old free tool that finds files faster than Windows Search does I install and update most of my apps with this Windows command now, and I stopped downloading sketchy installers
I install and update most of my apps with this Windows command now, and I stopped downloading sketchy installers Hisense U6SF 65-inch MiniLED TV: High Performance Meets Leisurely Convenience
Hisense U6SF 65-inch MiniLED TV: High Performance Meets Leisurely Convenience I stopped digging through Windows menus after I set up this one folder
I stopped digging through Windows menus after I set up this one folder