




Rambus has provided more details on its upcoming HBM4 memory controller, which offers some huge upgrades over current HBM3 and HBM3 memory controllers.
JEDEC is still finalizing the HBM4 memory specifications, with Rambus teasing its next-gen HBM4 memory controller that will be prepared for next-gen AI and data center markets, continuing to expand the capabilities of existing HBM DRAM designs.
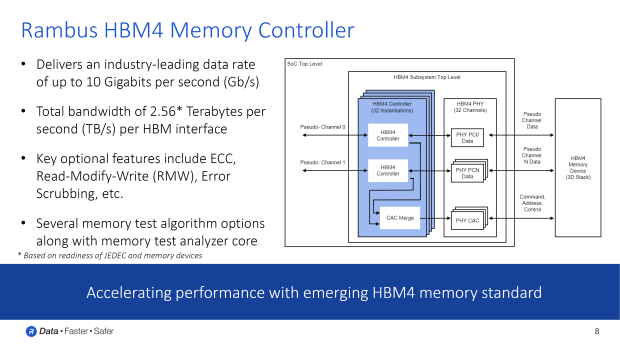
Popular Now: GeForce RTX 50 Series owners are reporting GPU Hotspots of 100+ degrees now that monitoring is availableRambus' new HBM4 controller will pump over 6.4Gb/s speeds per pin, which is faster than the first-gen HBM3 and has more bandwidth than faster HBM3E memory using the same 16-Hi stack and 64GB max capacity design. HBM4 starting bandwidth is at 1638GB/sec (1.63TB/sec) which is 33% faster than HBM3E and 2x faster than HBM3.
HBM3E memory operates at 9.6Gb/s speeds with up to 1.229TB/sec of memory bandwidth per stack, while HBM4 memory will offer up to 10Gb/s speeds and a much bigger 2.56TB/sec of bandwidth per HBM interface. This is a 2x increase over the just-launched HBM3E, but the full capabilities of HBM4 memory won't be realized for a while yet (NVIDIA's next-gen Rubin R100 will use HBM4 in 2026).

Rambus talked about some of the other features of HBM4, which include ECC, RMW (Read-Modify-Write), Error Scrubbing, and more.
- Read more: Rambus unveils industry-first HBM4 controller IP
- Read more: SK hynix's next-gen HBM4 tape out in October: for NVIDIA Rubin R100 AI GPU
- Read more: Samsung's next-gen HBM4 to enter mass production by the end of 2025
- Read more: Samsung to manufacture logic dies for next-gen HBM4 memory on 4nm node
- Read more: NVIDIA, TSMC, SK hynix form 'triangular alliance' for next-gen AI GPUs + HBM4
South Korean memory giant SK hynix is the only company mass-producing new 12-layer HBM3E memory with up to 36GB capacities and 9.6Gbps speeds, but next-gen HBM4 memory from SK hynix is expected to tape out next month, while Samsung is gearing into HBM4 mass production before the end of 2025, with tape out expected in Q4 2024.

We're expecting the next-gen NVIDIA Rubin R100 AI GPUs to use a 4x reticle design (compared to Blackwell with 3.3x reticle design) and made on TSMC's bleeding-edge CoWoS-L packaging technology on the new N3 process node. TSMC recently talked about up to 5.5x reticle size chips arriving in 2026, featuring a 100 x 100mm substrate that would handle 12 HBM sites, versus 8 HBM sites on current-gen 80 x 80mm packages.
TSMC will be shifting to a new SoIC design that will allow larger than 8x reticle size on a bigger 120 x 120mm package configuration, but as Wccftech points out, these are still being planned, so we can probably expect somewhere around the 4x reticle size for Rubin R100 AI GPUs.
 SK hynix's next-gen HBM4 tape out in October: ready for NVIDIA's future-gen Rubin R100 AI GPU
SK hynix's next-gen HBM4 tape out in October: ready for NVIDIA's future-gen Rubin R100 AI GPU This data center AI chip roadmap shows NVIDIA will dominate far into 2027 and beyond
This data center AI chip roadmap shows NVIDIA will dominate far into 2027 and beyond Samsung's next-gen HBM4 to enter mass production by the end of 2025, ready for next-gen AI GPUs
Samsung's next-gen HBM4 to enter mass production by the end of 2025, ready for next-gen AI GPUs Rambus unveils industry-first HBM4 controller IP, ready to super-speed next-gen AI workloads
Rambus unveils industry-first HBM4 controller IP, ready to super-speed next-gen AI workloads Future of next-gen HBM: HBM4, HBM5, HBM6, HBM7, and HBM8 teased with 15,000W AI GPUs by 2038
Future of next-gen HBM: HBM4, HBM5, HBM6, HBM7, and HBM8 teased with 15,000W AI GPUs by 2038 Bethesda gives news on Elder Scrolls 6, confirms 4 Fallout projects, new Starfield content
Bethesda gives news on Elder Scrolls 6, confirms 4 Fallout projects, new Starfield content GTA 6 can be ordered and delivered through Uber Eats
GTA 6 can be ordered and delivered through Uber Eats Zenimax Online Studios leaders, including studio head, exiting as part of Xbox cuts
Zenimax Online Studios leaders, including studio head, exiting as part of Xbox cuts Steam made a record $11 billion in just six months, analyst firm estimates
Steam made a record $11 billion in just six months, analyst firm estimates GeForce RTX 50 Series owners are reporting GPU Hotspots of 100+ degrees now that monitoring is available
GeForce RTX 50 Series owners are reporting GPU Hotspots of 100+ degrees now that monitoring is available Valve is now supplying replacement Steam Deck LCD batteries again, after reportedly ceasing support
Valve is now supplying replacement Steam Deck LCD batteries again, after reportedly ceasing support Intel Core Ultra 400 'Nova Lake' Series details leak, CPU naming and release dates
Intel Core Ultra 400 'Nova Lake' Series details leak, CPU naming and release dates Lenovo's Legion R9000P laptop has the world's first Inkjet-printed OLED display from TCL
Lenovo's Legion R9000P laptop has the world's first Inkjet-printed OLED display from TCL This PC gamer turned old SSDs into custom Steam game cartridges with printed cover art and cases
This PC gamer turned old SSDs into custom Steam game cartridges with printed cover art and cases XPG launches new ergonomic gaming chairs, the NIMBUS and NIMBUS PLUS
XPG launches new ergonomic gaming chairs, the NIMBUS and NIMBUS PLUS SteelSeries Arctis Nova 7 Wireless Gen 2 Headset Review - New and Improved, But Is It Enough?
SteelSeries Arctis Nova 7 Wireless Gen 2 Headset Review - New and Improved, But Is It Enough? AMD Ryzen 7 7700X3D Review - Days of Future Past
AMD Ryzen 7 7700X3D Review - Days of Future Past Samsung 990 2TB SSD Review - Ninth Gen QLC at PCIe Gen4 Speeds
Samsung 990 2TB SSD Review - Ninth Gen QLC at PCIe Gen4 Speeds ASUS ExpertBook Ultra (Panther Lake) 14" Business Laptop Review
ASUS ExpertBook Ultra (Panther Lake) 14" Business Laptop Review ASUS ROG Raikiri II Xbox Wireless Controller Review - Ready to Take Control
ASUS ROG Raikiri II Xbox Wireless Controller Review - Ready to Take Control MOZA FMP18 Panel Bundle Review: authentic F/A-18 Hornet cockpit controls for flight sims
MOZA FMP18 Panel Bundle Review: authentic F/A-18 Hornet cockpit controls for flight sims Micron 6600 ION 245.76TB Enterprise SSD Review - Best in Class Programming Speeds
Micron 6600 ION 245.76TB Enterprise SSD Review - Best in Class Programming Speeds MOZA MA3F EFCM Flight Control Module Review: authentic Airbus A320 autopilot panel for simulators
MOZA MA3F EFCM Flight Control Module Review: authentic Airbus A320 autopilot panel for simulators Turtle Beach Stealth Pro II Wireless Gaming Headset Review - Premium Sound, Fantastic Features
Turtle Beach Stealth Pro II Wireless Gaming Headset Review - Premium Sound, Fantastic Features MOZA MGX1000 Instrument Panel Review: a realistic Garmin G1000 replica for immersive flight sims
MOZA MGX1000 Instrument Panel Review: a realistic Garmin G1000 replica for immersive flight sims I stopped digging through Windows menus after I set up this one folder
I stopped digging through Windows menus after I set up this one folder Don't sell your Windows laptop until you do these things
Don't sell your Windows laptop until you do these things 6 PC cleaning mistakes to avoid for safer hardware maintenance
6 PC cleaning mistakes to avoid for safer hardware maintenance Phison and Intel Take Aim at Local AI's Memory Wall with aiDAPTIV
Phison and Intel Take Aim at Local AI's Memory Wall with aiDAPTIV How to Remap Keyboard Keys in Windows using Microsoft PowerToys
How to Remap Keyboard Keys in Windows using Microsoft PowerToys 7 tips to organize your Windows files for faster, easier access
7 tips to organize your Windows files for faster, easier access Intel Arc G3 Extreme first impressions with MSI's Claw 8 EX AI+ - Incredible power for an extreme price
Intel Arc G3 Extreme first impressions with MSI's Claw 8 EX AI+ - Incredible power for an extreme price How to fix Wi-Fi Adapter Not Working on Windows laptops: troubleshooting tips
How to fix Wi-Fi Adapter Not Working on Windows laptops: troubleshooting tips Hisense U7SG 4K TV: Modern Entertainment for the New Age
Hisense U7SG 4K TV: Modern Entertainment for the New Age 6 underrated Microsoft Word features worth using to boost your productivity
6 underrated Microsoft Word features worth using to boost your productivity