



My name is Ganesh [Venkataramanan, Tesla director and Dojo boss] and I lead Dojo. It's an honor to present this project on behalf of the multi-disciplinary Tesla team that is working on this project.
As you saw from Milan, there's an insatiable demand for speed, actualized capacity for neural network training -- and Elon prefetched this, and a few years back he asked us to design a super-fast training computer, and that's how we started Project Dojo.

Our goal is to achieve best AI training performance and support all these larger, more complex models that Andre's team are dreaming of and be power-efficient, and cost-effective at the same time. So we thought about how to build this, and we came up with a Distributed Compute Architecture.
After all, all the training computers out there are distributed computers in one form or the other, they have compute elements -- in the box out here -- connected with some kind of network, in this case it's a two-dimensional network. But it could be any different network: CPU, GPU, accelerators, all of them have compute, little memory, and network.
But one thing which is common trend amongst this, it's easy to scale the compute -- it's very difficult to scale up bandwidth -- and extremely difficult to reduce latencies. You'll see how our design point, catered to that, how our philosophy addressed these aspects of traditional limits.
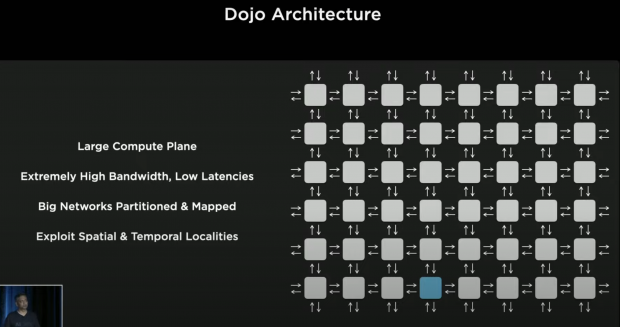
For Dojo, we envisioned a Large Compute Plane filled with very robust compute elements, backed with large pool of memory and interconnected with very high bandwidth and low latency fabric and in a 2D mesh format. Onto this, for extreme-scale -- big neural networks will be partitioned and mapped to extract different parallelism, model, graph, data parallelism...
And then a neural compiler of ours with exploit spatial and temporal locality, such that it can reduce communication footprint to local zones and reduce global communication -- and if we do that, our bandwidth utilization can keep scaling with the Plane of Compute that we designed out here.

We wanted to attack this all the way, top to bottom, of the stack -- and remove any bottlenecks, at any of these levels. Let's start this journey with an inside-out fashion, starting with the chip.
As I described, chips have compute elements -- ours, smallest entity of scale is called a Training Node. The
choice of the node is important, to achieve seamless scaling -- if you go too small, it will run fast -- but the overheads of synchronization and software will dominate. If you pick it too big, it will have complex implementations and real hardware and ultimately run into memory bottleneck issues.
"Because we wanted to address latency and bandwidth as primary optimization points -- let's see how we think about doing this. What we did was pick the farthest distance a signal could travel in a very high clock cycle, in this case 2GHz+ and we drew a box around it -- this is the smallest latency that a signal can travel, it's 1 cycle at a very high frequency".
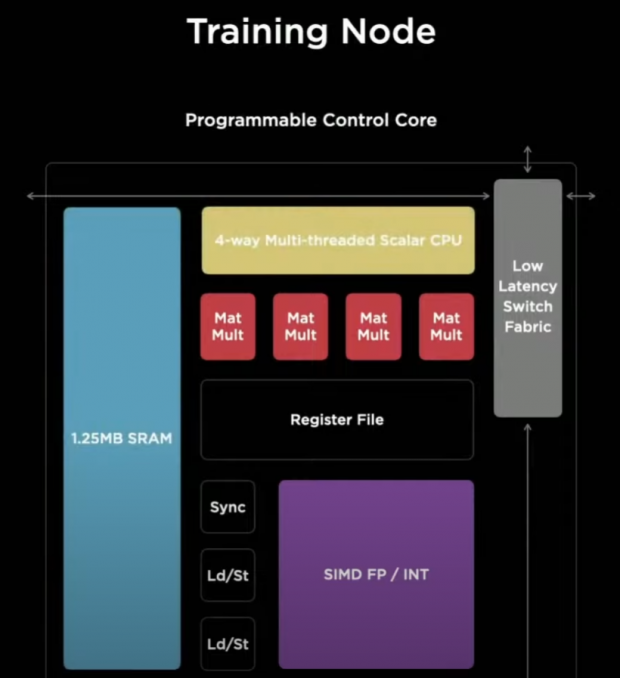
And then we filled up the box with wires to the brink -- this is the highest bandwidth you can feed the box with, and then we added machine learning compute underneath, and then a large pool of SRAM (1.25MB) and last but not the least -- a programmable core to control, and this gave us our High-Performance Training Node.

Tesla director Ganesh Venkataramanan continues, explaining the High-Performance Training Node as a 64-bit Superscalar CPU optimized around matrix multiplier units and vector MD, it supports FP32, BFP16, and a new format: CFP8. Configurable FP8, and it is backed by 1.25MB High-Speed ECC Protected SRAM and the low-latency high-bandwidth fabric that we designed".

This might be our smallest entity of scale but it packs a big punch, more than 1 TFLOP of compute in our smallest entity of scale.
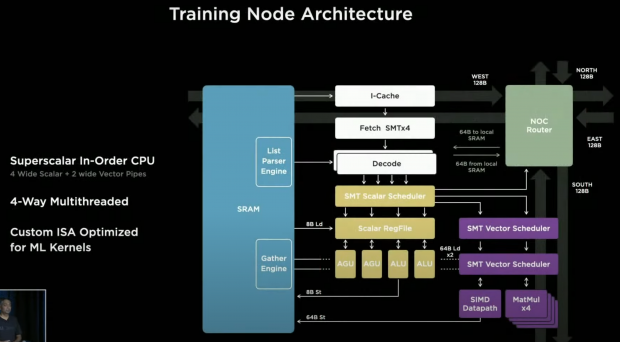
"So let's look at the architecture of this -- the computer architects out here may recognize this, this is a pretty capable architecture as soon as you see this. It is a superscalar in-order CPU with 4 wide scalar and 2 wide vector pipes, we call it in-order although the vector and scalar pipes can go out of order -- but for the purist's out there we still call it in-order".
"It also has 4-way multi-threaded, this increases utilization because we do compute and data transfers simultaneously, and our custom ISA (the Instruction Set Architecture) is fully-optimized for machine learning workloads".
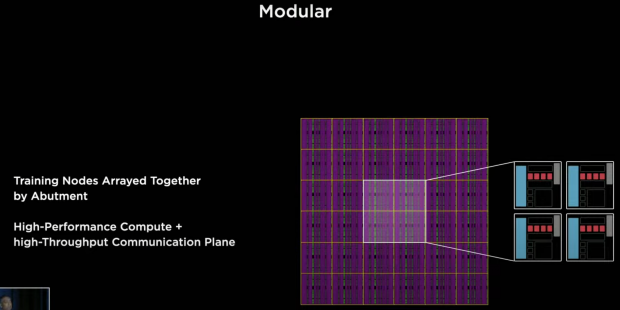
Even in the physical realm, we made it extremely modular -- such that we can abutment these Training Nodes in any direction and start farming the compute plane that we envisioned.

When we clicked together 354 of these Training Nodes, we get our Compute Array -- it's capable of delivering 333 TFLOPs of machine learning compute -- and of course, the high-bandwidth fabric that interconnects these.
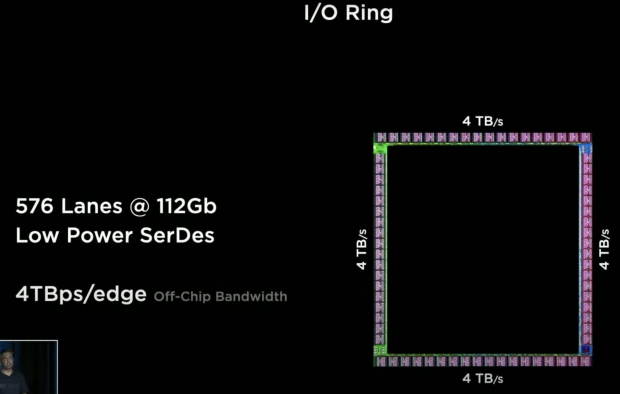
"Around this compute array, we surrounded it with high-speed, low-power SerDes -- 576 of them, to enable us to have extreme I/O bandwidth coming out of this chip. just to give you a comparison point: This is more than 2x the bandwidth coming out of the state of the art networking switch chips that are out there today, and network switches are meant to be the gold standard for I/O bandwidth".
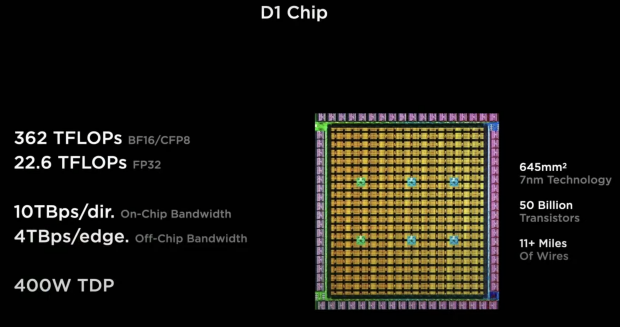
"If you put all of it together, we get a training-optimized chip: our D1 chip. This chip is manufactured on 7nm, it packs 50 billion transistors in 645mm2. One thing you'd notice: 100% of the area out here is going to machine learning training and bandwidth -- there is no dark silicon, there is no legacy support. This is a pure machine-learning machine".
"This [pulling the Tesla D1 chip from his pocket] is the D1 chip, in a flip-chip BGA package, this was entirely designed by the Tesla team internally, all the way from the architecture to the GDS out and package. This chip is like a GPU level compute, with a CPU level flexibility, and twice the network chip-level I/O bandwidth.
"If I were to plot the I/O bandwidth on the vertical scale versus teraflops of compute that is available in the state-of-the-art machine learning chips out there, including some of the startups -- you can easily see why our design point excels beyond par.".
Now that we had this fundamental physical building block, how to design the system around it... let's see. Since D1 chips can seamlessly connect without any glue to each other, we just started putting them together -- we just put, 500,000 Training Nodes together to farm our Compute Plane -- this is 1500 D1 chips seamlessly connected to each other.
And then we add Dojo interface processors on each end, this is the host bridge to typical hosts in the datacenters, it's connected with PCIe 4.0 on one side with a high bandwidth fabric to our Compute Plane. The interface processors provide not only the host bridge, but high bandwidth DRAM shared memory for the Compute Plane.
In addition, the interface p processors can allow us to have a higher Radix network connection. In order to achieve this Compute Plane, we had to come up with a new way of integrating these chips together.

This is what we call a Training Tile -- this is the unit of scale for our system. This is a groundbreaking integration of 25 known good D1 dies onto a finite wafer process tightly integrated such that it preserves the bandwidth between them -- the maximum bandwidth is preserved there, and in addition -- we generated a connector -- a high bandwidth, high-density connector that preserves the bandwidth coming out of this Training Tile.

This tile gives up 9 PFLOPs of compute with a massive bandwidth I/O bandwidth coming out of it. This, perhaps, is the biggest organic MCM in the chip industry. Multi-Chip Module.
It was not easy to design this, there were no tools that existed -- all the tools were croaking, even our compute cluster couldn't handle it. We had to, our engineers, came up with different ways of solving this, they created new methods to make this a reality.


Now that we have our Compute Plane Tile with high-bandwidth I/O, we had to feed it with power, and here is we came up with a new way of feeding power -- vertically, we created a custom voltage regulator module that could be reflowed directly onto this finite wafer, so what we did out here is we got chip, package, and bought PCB level technology of reflow onto this finite wafter technology.
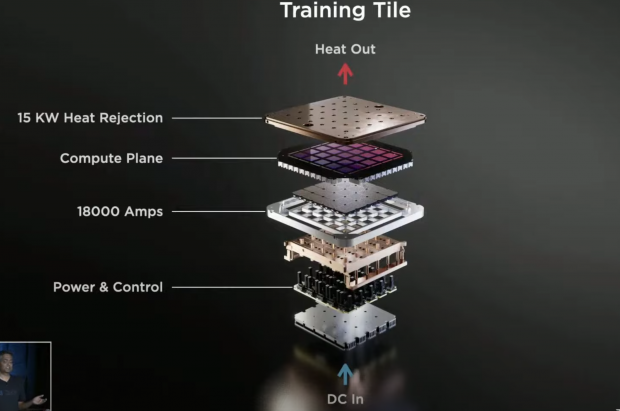
This is a lot of integration already out here, but we didn't stop here -- we integrated the entire electrical, thermal, and mechanical pieces out here to form our Training Tile -- fully integrated -- interfacing with a 52V DC input.
It's unprecedented. This is an amazing piece of engineering.
Our Compute Plane in completely orthogonal to power supply and cooling, that makes high bandwidth Compute Planes possible.

What it is -- is a 9-petaflop Training Tile. This becomes our unit of scale for our system, and this -- [pulls out the big boy in person, in his hands] is real.

I can't believe I'm holding 9 petaflops out here.
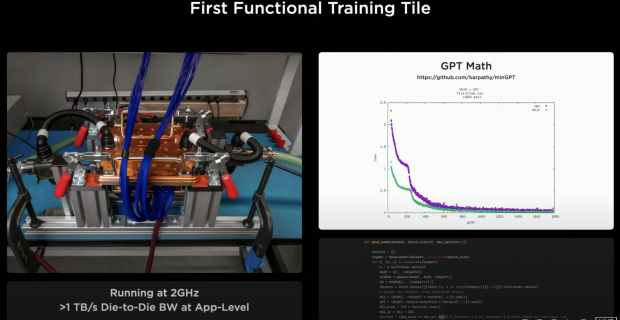
"And in fact, last week we got our first functional Training Tile and on a limited, limited cooling benchtop setup -- we got some networks running and I was told Andre doesn't believe we can run networks, until we could run one of his creations. Andre -- this is minGPT running on Dojo [laughs] do you believe it?"
Next up, how to form a Compute Cluster out of it?

By now you must have realised our modularity story is pretty strong, we just put together some tiles -- we just tied together tiles -- a 2 x 3 Tile in a Tray makes our Training Matrix, and 2 Trays in a Cabinet gives 100PFLOPs of compute.
Did we stop here? No [laughs].

We just integrated seamlessly, we broke the Cabinet walls, we integrated these Tiles seamlessly all the way through, preserving the bandwidth -- there's no bandwidth divet out here, there's no bandwidth cliffs. All the tiles are seamlessly connected with the same bandwidth... and with this...

We have an ExaPOD -- this is 1 exaflop of compute in 10 Cabinets. It's more than 1 million Training Nodes that you saw, we paid meticulous attention to that Training Node, and there are 1 million Training nodes here with uniform bandwidth.
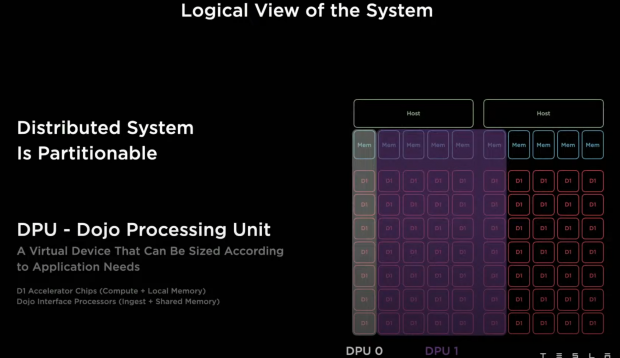
Not just the hardware, the software aspects are so important to ensure scaling -- and not every job requires a huge cluster, so we planned for it right from the get-go.
Our Compute Plane can be subdivided, they can be partitioned, into units called Dojo Processing Unit -- a DPU consists of one or more D1 chips, it also has our interface processor and one or more hosts. This can be scaled up or down, as per the needs of any network running on it.
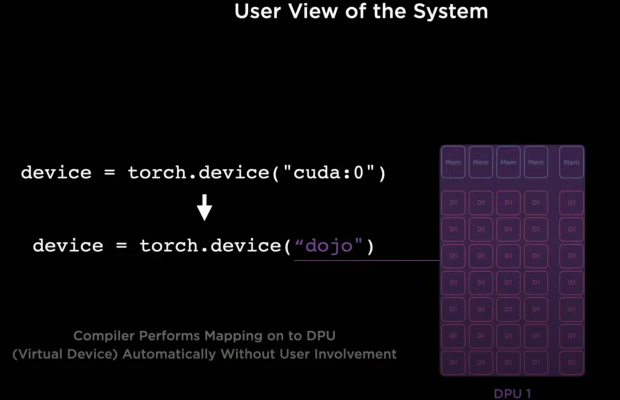
What does the user have to do? They have to change their scripts minimally, and this is because of our strong compiler suite. It takes care of fine-grain parallelism and mapping the neural networks very efficiently onto our Compute Plane.
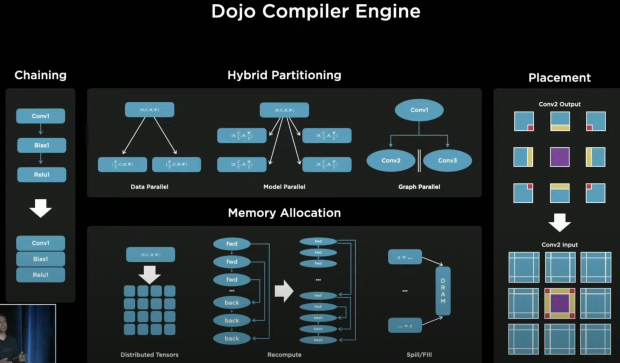
Our compiler uses multiple techniques to extract parallelism, it can transform the networks to achieve not only fine-grain parallelism using data model graph parallelism techniques, it also can do optimizations to reduce memory footprints.
One thing because of our high bandwidth nature of the fabric is enabled out here, modern parallelism could not have been extended to the same level as what we can. It was limited to chip boundaries, now we can -- because of our high bandwidth -- we can extend it to Training Tiles and beyond. Thus, large networks can efficiently mapped here at low batch sizes, and extract utilization and new levels of performance.
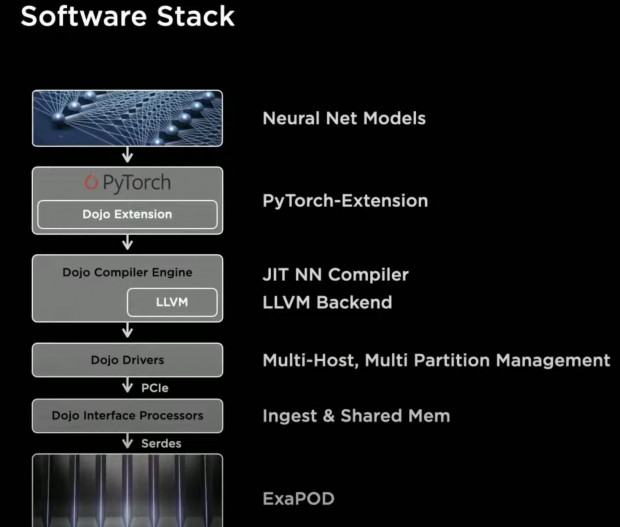
In addition, our compiler is capable of handling high-level dynamic control flows like loops, fennels, etc. Our compiler engine is just part of our entire software suite, the stack consists of extension to PyTorch that ensures the same user-level interfaces that ML scientists are used to, and our compiler generates code on-the-fly such that it can be re-used for subsequent execution. It has an LLVM Backend that generates the binary for the hardware, and this ensures we can create optimized code for the hardware without relying on even a single line of handwritten kernel.
Our driver stack takes care of the multi-host, multi-partitioning that you saw a few slides back, and then we also have profilers and debuggers in our software stack.

So with all this, we integrated in a vertical fashion -- we broke the traditional barriers to scaling, and that's how we got modularity up and down the stack, to add to new levels of performance.

To sum it all, this is what it will be: it will be the fastest AI training computer -- 4x the performance at the same cost, 1.3x better performance-per-watt -- that is energy-saving, and 5x smaller footprint.
This will be Dojo computer.
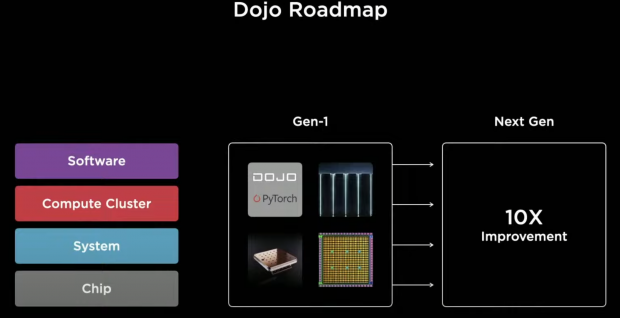
And we are not done -- we are assembling our first Cabinets pretty soon, and we have a whole next generation planned already, we're thinking about 10x more with different aspects that we can do, all the way from silicon to the system, again.
We will have this journey, again. We are recruiting heavily for all of these areas.

 PlayStation QA team may be the secret to Project Amethyst's quick turnaround
PlayStation QA team may be the secret to Project Amethyst's quick turnaround Elon Musk says Tesla's next-gen AI5 chip is 40x faster than AI4: calls it a 'beautiful chip'
Elon Musk says Tesla's next-gen AI5 chip is 40x faster than AI4: calls it a 'beautiful chip' id Software not a support studio after layoffs, reportedly working on new Doom project
id Software not a support studio after layoffs, reportedly working on new Doom project Apple sues OpenAI, accusing it of engaging in a 'strategy to extract Apple's confidential information'
Apple sues OpenAI, accusing it of engaging in a 'strategy to extract Apple's confidential information' Another RTX 5090 power connector melted, and even ASRock TempGuard failed to save this one
Another RTX 5090 power connector melted, and even ASRock TempGuard failed to save this one Reverse scam: Redditor orders a Ryzen 7 7800X3D but gets blessed with a 9800X3D instead
Reverse scam: Redditor orders a Ryzen 7 7800X3D but gets blessed with a 9800X3D instead Colorful iGame Shadow II DDR5 memory with CXMT ICs hits 8600 MT/s
Colorful iGame Shadow II DDR5 memory with CXMT ICs hits 8600 MT/s ASRock says there are no plans to sell its Taichi 10th anniversary concept components
ASRock says there are no plans to sell its Taichi 10th anniversary concept components Sony CEO sells $4.7 million worth of stock days after PlayStation announces disc phase out
Sony CEO sells $4.7 million worth of stock days after PlayStation announces disc phase out Black Flag Resynced is a win for Ubisoft, pirate remaster achieves 2 million sales in 24 hours
Black Flag Resynced is a win for Ubisoft, pirate remaster achieves 2 million sales in 24 hours Giveaway: Win an NZXT H6 RGB+ Case, Kraken Elite AIO, RGB Fans and 1200W PSU
Giveaway: Win an NZXT H6 RGB+ Case, Kraken Elite AIO, RGB Fans and 1200W PSU Micron 6600 ION 245.76TB Enterprise SSD Review - Best in Class Programming Speeds
Micron 6600 ION 245.76TB Enterprise SSD Review - Best in Class Programming Speeds MOZA MA3F EFCM Flight Control Module Review: authentic Airbus A320 autopilot panel for simulators
MOZA MA3F EFCM Flight Control Module Review: authentic Airbus A320 autopilot panel for simulators Turtle Beach Stealth Pro II Wireless Gaming Headset Review - Premium Sound, Fantastic Features
Turtle Beach Stealth Pro II Wireless Gaming Headset Review - Premium Sound, Fantastic Features MOZA MGX1000 Instrument Panel Review: a realistic Garmin G1000 replica for immersive flight sims
MOZA MGX1000 Instrument Panel Review: a realistic Garmin G1000 replica for immersive flight sims Simagic Zeus Formula Steering Wheel Review: premium build and advanced inputs for F1 racing
Simagic Zeus Formula Steering Wheel Review: premium build and advanced inputs for F1 racing GIGABYTE X870E Aero X3D Dark Wood Review - A woody goody
GIGABYTE X870E Aero X3D Dark Wood Review - A woody goody The Super Mario Galaxy Movie (2026) 4K Ultra HD Blu-ray Review
The Super Mario Galaxy Movie (2026) 4K Ultra HD Blu-ray Review KTC H49S66 5K2K (5120x1440) 49-inch 180Hz Gaming Monitor Review
KTC H49S66 5K2K (5120x1440) 49-inch 180Hz Gaming Monitor Review HighPoint Rocket 1604L Gen5 x16 NVMe Software RAID AIC Review: half the price with full 59 GB/s speed
HighPoint Rocket 1604L Gen5 x16 NVMe Software RAID AIC Review: half the price with full 59 GB/s speed Next Level Racing ERS3 Haptic Seat Review: immersive sim racing comfort with integrated haptics
Next Level Racing ERS3 Haptic Seat Review: immersive sim racing comfort with integrated haptics Don't sell your Windows laptop until you do these things
Don't sell your Windows laptop until you do these things 6 PC cleaning mistakes to avoid for safer hardware maintenance
6 PC cleaning mistakes to avoid for safer hardware maintenance Phison and Intel Take Aim at Local AI's Memory Wall with aiDAPTIV
Phison and Intel Take Aim at Local AI's Memory Wall with aiDAPTIV How to Remap Keyboard Keys in Windows using Microsoft PowerToys
How to Remap Keyboard Keys in Windows using Microsoft PowerToys 7 tips to organize your Windows files for faster, easier access
7 tips to organize your Windows files for faster, easier access Intel Arc G3 Extreme first impressions with MSI's Claw 8 EX AI+ - Incredible power for an extreme price
Intel Arc G3 Extreme first impressions with MSI's Claw 8 EX AI+ - Incredible power for an extreme price How to fix Wi-Fi Adapter Not Working on Windows laptops: troubleshooting tips
How to fix Wi-Fi Adapter Not Working on Windows laptops: troubleshooting tips Hisense U7SG 4K TV: Modern Entertainment for the New Age
Hisense U7SG 4K TV: Modern Entertainment for the New Age 6 underrated Microsoft Word features worth using to boost your productivity
6 underrated Microsoft Word features worth using to boost your productivity Level Up Your PC Gaming with these Fantastic ASUS Prime Day Deals on GPUs, Motherboards, and More
Level Up Your PC Gaming with these Fantastic ASUS Prime Day Deals on GPUs, Motherboards, and More