




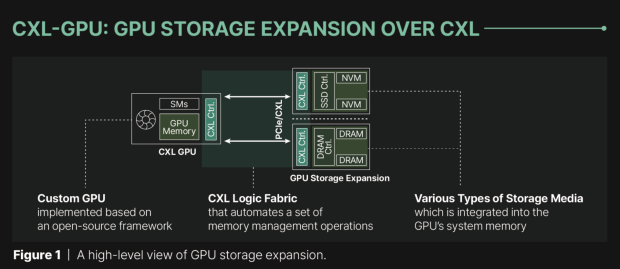
Panmnesia is a company you probably haven't heard of until today, but the KAIST startup has unveiled its cutting-edge IP that enables adding external memory to AI GPUs over the CXL protocol over PCIe, which enables new levels of memory capacity for AI workloads.
The current fleets of AI GPUs and AI accelerators use their on-board memory -- usually super-fast HBM -- but this is limited to smaller quantities like 80GB on the current NVIDIA Hopper H100 AI GPU. AMD and NVIDIA's next-gen AI chip offerings will usher in up to 141GB HBM3E (H200 AI GPU from NVIDIA) and up to 192GB HBM3E (B200 AI GPU from NVIDIA, and Instinct MI300X from AMD).
But now, Panmnesia's new CXL IP will let GPUs access memory from DRAM and SSDs, expanding the memory capacity from its built-in HBM memory... very nifty. The South Korean Institute (KAIST) startup bridges the connectivity with CXL over PCIe links, which means mass adoption is easy with this new tech. Regular AI accelerators don't have the subsystems required to connect with and use CXL for memory expansion directly, relying on solutions like UVM (Unified Virtual Memory) which is slower, defeating the purpose completely... which is where Panmnesia's new IP comes into play.
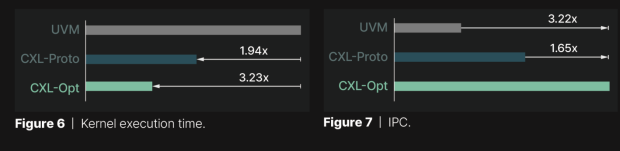
Panmnesia benchmarked its own "CXL-Opt" solution against prototypes from Samsung and Meta, which they've labeled as "CXL-Proto". CXL-Opt has much lower round-trip latency, which is the time taken for data to travel from the GPU to the memory, and then back again. Panmnesia's new CXL-Pro enjoyed a two-digit nanosecond latency, versus the 250ns of latency of its competitors. CXL-Opt's execution time is also far less than UVM, as it hits IPC performance improvements of 3.22x over UVM. Impressive.
The new CXL-Pro solution from Panmnesia could make for big waves in the AI GPU and AI accelerator market, acting as a solution between stacking HBM memory chips and moving towards a far more efficient solution. Panmnesia is one of the first with its new CXL IP, so it'll be interesting to see how we go from here.

 Amazon Web Services' Trainium3 AI chips - over 1000W of power and liquid cooled
Amazon Web Services' Trainium3 AI chips - over 1000W of power and liquid cooled Rambus unveils industry-first HBM4 controller IP, ready to super-speed next-gen AI workloads
Rambus unveils industry-first HBM4 controller IP, ready to super-speed next-gen AI workloads Future of next-gen HBM: HBM4, HBM5, HBM6, HBM7, and HBM8 teased with 15,000W AI GPUs by 2038
Future of next-gen HBM: HBM4, HBM5, HBM6, HBM7, and HBM8 teased with 15,000W AI GPUs by 2038 NVIDIA unveils GB200 NVL4: four Blackwell GPUs, dual Grace GPUs, 1.7TB memory, 5400W of power
NVIDIA unveils GB200 NVL4: four Blackwell GPUs, dual Grace GPUs, 1.7TB memory, 5400W of power Rambus details HBM4 memory controller: up to 10Gb/s, 2.56TB/sec bandwidth, 64GB per stack
Rambus details HBM4 memory controller: up to 10Gb/s, 2.56TB/sec bandwidth, 64GB per stack Diablo 4 Season 14 changes how the best items in the game work
Diablo 4 Season 14 changes how the best items in the game work AMD updates FSR SDK with FSR 4.1.1 support for RDNA 3 and improved FSR Ray Regeneration 1.2.0
AMD updates FSR SDK with FSR 4.1.1 support for RDNA 3 and improved FSR Ray Regeneration 1.2.0 Valve offers update on Steam Deck 2, says it's close but still has one issue to solve
Valve offers update on Steam Deck 2, says it's close but still has one issue to solve Creative's new compact XF1 desktop PC speakers support Hi-Res audio
Creative's new compact XF1 desktop PC speakers support Hi-Res audio 8BitDo unveils new Nintendo 64-inspired Retro 87 Keyboard
8BitDo unveils new Nintendo 64-inspired Retro 87 Keyboard OLED buyer becomes victim of Amazon scam, receives broken 240Hz OLED screen instead of 540Hz OLED they initially ordered
OLED buyer becomes victim of Amazon scam, receives broken 240Hz OLED screen instead of 540Hz OLED they initially ordered Google taps MediaTek to build its next Triggerfish TPU chip launching in 2027
Google taps MediaTek to build its next Triggerfish TPU chip launching in 2027 Samsung announces world's first UFS 5.0 chip with 10.8 GB/s read and 9.5 GB/s write speeds
Samsung announces world's first UFS 5.0 chip with 10.8 GB/s read and 9.5 GB/s write speeds GTA 6 will feature a story chapter system like Red Dead Redemption 2
GTA 6 will feature a story chapter system like Red Dead Redemption 2 AMD confirms Adrenalin 26.6.2 driver fails to launch on Windows 10, recommends rolling back
AMD confirms Adrenalin 26.6.2 driver fails to launch on Windows 10, recommends rolling back Dell XPS 14 (2026) Laptop Review - Premium Quality, Impressive Performance
Dell XPS 14 (2026) Laptop Review - Premium Quality, Impressive Performance Ocypus Sigma F36 BK ARGB Cooling Fan Review: high airflow and unified design in one frame
Ocypus Sigma F36 BK ARGB Cooling Fan Review: high airflow and unified design in one frame PCCooler CPS RZ820 Display Review: a flagship-level CPU air cooler with an LCD screen
PCCooler CPS RZ820 Display Review: a flagship-level CPU air cooler with an LCD screen Speed Racer (2008) 4K Ultra HD Blu-ray Review: a stunning remaster of the cult classic
Speed Racer (2008) 4K Ultra HD Blu-ray Review: a stunning remaster of the cult classic MOAIPLAY ORA PRO G1 850W ATX 3.1 PSU Review: high efficiency and 10-year warranty for $119.99
MOAIPLAY ORA PRO G1 850W ATX 3.1 PSU Review: high efficiency and 10-year warranty for $119.99 Navman MiVue Smart True 4K Surround Dashcam Review - Seeing In All Directions At Once
Navman MiVue Smart True 4K Surround Dashcam Review - Seeing In All Directions At Once IQUNIX Magi96 Pro Aluminum Low Profile Mechanical Keyboard Review - Premium Build, Satisfying Sound
IQUNIX Magi96 Pro Aluminum Low Profile Mechanical Keyboard Review - Premium Build, Satisfying Sound Asetek Forte S-Series Racing Simulator Bundle Review
Asetek Forte S-Series Racing Simulator Bundle Review Razer Pro Type Ergo Wireless Split Ergonomic Keyboard Review - Built for Comfort and Support
Razer Pro Type Ergo Wireless Split Ergonomic Keyboard Review - Built for Comfort and Support Level Up Your PC Gaming with these Fantastic ASUS Prime Day Deals on GPUs, Motherboards, and More
Level Up Your PC Gaming with these Fantastic ASUS Prime Day Deals on GPUs, Motherboards, and More GIGABYTE Wants to Kickstart Your New Gaming PC or Upgrade with These Limited-Time Deals
GIGABYTE Wants to Kickstart Your New Gaming PC or Upgrade with These Limited-Time Deals 7 Windows settings to change right after installation for better privacy, security, and performance
7 Windows settings to change right after installation for better privacy, security, and performance I stopped Windows 11 notifications from interrupting me with Do Not Disturb, Focus, and a priority list
I stopped Windows 11 notifications from interrupting me with Do Not Disturb, Focus, and a priority list I read the Windows Backup app screen carefully, and it does not back up what most people think
I read the Windows Backup app screen carefully, and it does not back up what most people think Low Sound Volume on Windows 11? How to fix audio issues and restore normal volume
Low Sound Volume on Windows 11? How to fix audio issues and restore normal volume 8 Critical Warning Signs You Should Never Ignore in Windows 11
8 Critical Warning Signs You Should Never Ignore in Windows 11 This Windows security feature protects Documents from ransomware, but it is off by default
This Windows security feature protects Documents from ransomware, but it is off by default Windows 11 already has a voice typing tool, and it is the one most people are not using
Windows 11 already has a voice typing tool, and it is the one most people are not using