




Meta has a nice surprise today: its latest large language model (LLM), Llama 3. The company explains its new Llama 3 8B contains 8 billion parameters, while its Llama 3 70B features 70 billion parameters.
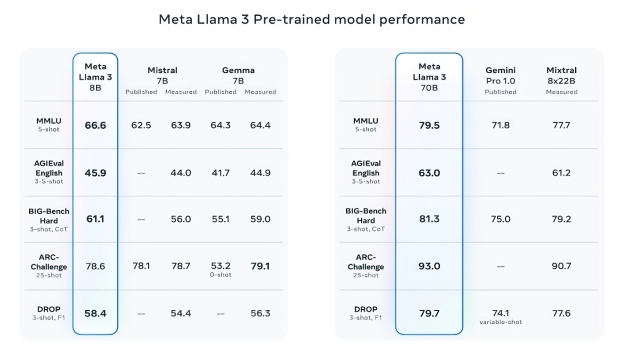
Meta promises a gigantic increase in performance over the previous Llama 2 8B and Llama 2 70B models, with the company claiming that Llama 3 8B and Llama 3 70B are some of the best-performing generative AI models available today, trained on two custom-built 24,000 GPU clusters.
The company trained its new Llama 3 model on over 15 trillion tokens that were all collected from "publicly available sources," and that Met'a training dataset is 7x larger than what was used for Llama 2, and that includes 4x more code.
Meta's new Llama 3 takeaways:
- Today, we're introducing Meta Llama 3, the next generation of our state-of-the-art open source large language model.
- Llama 3 models will soon be available on AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM, and Snowflake, and with support from hardware platforms offered by AMD, AWS, Dell, Intel, NVIDIA, and Qualcomm.
- We're dedicated to developing Llama 3 in a responsible way, and we're offering various resources to help others use it responsibly as well. This includes introducing new trust and safety tools with Llama Guard 2, Code Shield, and CyberSec Eval 2.
- In the coming months, we expect to introduce new capabilities, longer context windows, additional model sizes, and enhanced performance, and we'll share the Llama 3 research paper.
- Meta AI, built with Llama 3 technology, is now one of the world's leading AI assistants that can boost your intelligence and lighten your load-helping you learn, get things done, create content, and connect to make the most out of every moment. You can try Meta AI here.
You can read all the nerdy stuff from Meta's new Llama 3 model here.

 Phison's groundbreaking aiDAPTIV+ makes training AI easier by combining GPUs and SSDs
Phison's groundbreaking aiDAPTIV+ makes training AI easier by combining GPUs and SSDs Meta using over 100,000 NVIDIA H100 AI GPUs for Llama 4, Zuck: 'bigger than anything I've seen'
Meta using over 100,000 NVIDIA H100 AI GPUs for Llama 4, Zuck: 'bigger than anything I've seen' Meta gives US government its powerful AI after China took it and weaponized it
Meta gives US government its powerful AI after China took it and weaponized it Mark Zuckerberg teases $65B plan on building 1.3 million AI GPU datacenter in 2025
Mark Zuckerberg teases $65B plan on building 1.3 million AI GPU datacenter in 2025 Meta's huge 16,384 NVIDIA H100 AI GPU cluster: HBM3 memory crashed half of Llama 3 training
Meta's huge 16,384 NVIDIA H100 AI GPU cluster: HBM3 memory crashed half of Llama 3 training 007 First Light ditches Denuvo DRM just as first patch arrives packing a ton of bug fixes and some new content
007 First Light ditches Denuvo DRM just as first patch arrives packing a ton of bug fixes and some new content Microsoft's still working on Windows 11 File Explorer improvements, and it's now making deleting large files speedier
Microsoft's still working on Windows 11 File Explorer improvements, and it's now making deleting large files speedier Hacking group Anonymous targets Sony over deciding to kill PlayStation discs
Hacking group Anonymous targets Sony over deciding to kill PlayStation discs Top 5 PS Store pre-orders in US are all $100+ games
Top 5 PS Store pre-orders in US are all $100+ games Anthropic responds after Claude conversations appeared in Google Search results
Anthropic responds after Claude conversations appeared in Google Search results Steam Workshop maps infected players with malware and took over a 100,000-member Discord
Steam Workshop maps infected players with malware and took over a 100,000-member Discord MSI launches compact PRO MAX EDGE AI+ desktops, with up to Ryzen AI Max+ 395 and 128GB of memory
MSI launches compact PRO MAX EDGE AI+ desktops, with up to Ryzen AI Max+ 395 and 128GB of memory ASRock launches new 27-inch QHD QD-OLED Phantom Gaming monitors
ASRock launches new 27-inch QHD QD-OLED Phantom Gaming monitors Framework says current memory prices are 'far beyond anything we're able to absorb'
Framework says current memory prices are 'far beyond anything we're able to absorb' US data centers on track to use up 20% of the entire country's power by 2035
US data centers on track to use up 20% of the entire country's power by 2035 Thrustmaster T.Flight HOTAS 5 MSFS Edition Review
Thrustmaster T.Flight HOTAS 5 MSFS Edition Review SteelSeries Arctis Nova Pro Omni Wireless Headset Review - One Headset to Rule Them All
SteelSeries Arctis Nova Pro Omni Wireless Headset Review - One Headset to Rule Them All SteelSeries Arctis Nova 7 Wireless Gen 2 Headset Review - New and Improved, But Is It Enough?
SteelSeries Arctis Nova 7 Wireless Gen 2 Headset Review - New and Improved, But Is It Enough? AMD Ryzen 7 7700X3D Review - Days of Future Past
AMD Ryzen 7 7700X3D Review - Days of Future Past Samsung 990 2TB SSD Review - Ninth Gen QLC at PCIe Gen4 Speeds
Samsung 990 2TB SSD Review - Ninth Gen QLC at PCIe Gen4 Speeds ASUS ExpertBook Ultra (Panther Lake) 14" Business Laptop Review
ASUS ExpertBook Ultra (Panther Lake) 14" Business Laptop Review ASUS ROG Raikiri II Xbox Wireless Controller Review - Ready to Take Control
ASUS ROG Raikiri II Xbox Wireless Controller Review - Ready to Take Control MOZA FMP18 Panel Bundle Review: authentic F/A-18 Hornet cockpit controls for flight sims
MOZA FMP18 Panel Bundle Review: authentic F/A-18 Hornet cockpit controls for flight sims Micron 6600 ION 245.76TB Enterprise SSD Review - Best in Class Programming Speeds
Micron 6600 ION 245.76TB Enterprise SSD Review - Best in Class Programming Speeds MOZA MA3F EFCM Flight Control Module Review: authentic Airbus A320 autopilot panel for simulators
MOZA MA3F EFCM Flight Control Module Review: authentic Airbus A320 autopilot panel for simulators Printer Not Working in Windows? How to fix detection, print queues and drivers
Printer Not Working in Windows? How to fix detection, print queues and drivers The Ultimate Guide to Personalizing Your Windows 11 Taskbar
The Ultimate Guide to Personalizing Your Windows 11 Taskbar How to Turn Your Windows Laptop Into a Second Monitor with Miracast and Wireless Display in Minutes
How to Turn Your Windows Laptop Into a Second Monitor with Miracast and Wireless Display in Minutes 6 Mistakes to Avoid When Buying a Windows Laptop
6 Mistakes to Avoid When Buying a Windows Laptop I capped Windows Update's bandwidth with Delivery Optimization, and my downloads stopped choking
I capped Windows Update's bandwidth with Delivery Optimization, and my downloads stopped choking I use this decade-old free tool that finds files faster than Windows Search does
I use this decade-old free tool that finds files faster than Windows Search does I install and update most of my apps with this Windows command now, and I stopped downloading sketchy installers
I install and update most of my apps with this Windows command now, and I stopped downloading sketchy installers Hisense U6SF 65-inch MiniLED TV: High Performance Meets Leisurely Convenience
Hisense U6SF 65-inch MiniLED TV: High Performance Meets Leisurely Convenience I stopped digging through Windows menus after I set up this one folder
I stopped digging through Windows menus after I set up this one folder Don't sell your Windows laptop until you do these things
Don't sell your Windows laptop until you do these things