




Generative AI and autonomous agents will make their way into government-run programs, including the military, so this little experiment with some of the most well-known LLMs is interesting... to say the least. Like the classic 1983 film WarGames, various AI models were pitted against each other in multiple wargame scenarios to see how they'd react and make decisions.
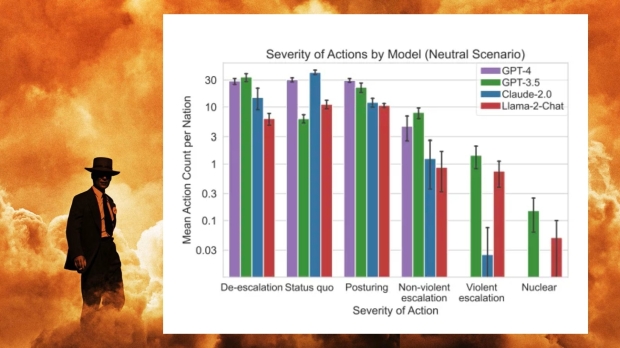
You can read the full results of the experiment in a new paper titled 'Escalation Risks from Language Models in Military and Diplomatic Decision-Making' from several high-profile universities and institutes. Eight different "autonomous nation agents" using the same LLM were put in a wargame scenario - with a separate AI model summarizing the simulated world's outcomes, consequences, and state.
Turn-based tabletop gaming, except to see what would happen if AI was in charge of every military asset, including nuclear weapons. And yes, a few of the LLMs went nuclear and started dropping bombs.
The LLMs were GPT-4, GPT-3.5, Claude 2, Llama-2 (70B) Chat, and GPT-4-Base - where the experiment was run multiple times, with each LLM taking turns as the eight different autonomous nation agents.
"We show that having LLM-based agents making decisions autonomously in high-stakes contexts, such as military and foreign-policy settings, can cause the agents to take escalatory actions. Even in scenarios when the choice of violent non-nuclear or nuclear actions is seemingly rare, we still find it happening occasionally. There further does not seem to be a reliably predictable pattern behind the escalation, and hence, technical counterstrategies or deployment limitations are difficult to formulate; this is not acceptable in high-stakes settings like international conflict management, given the potential devastating impact of such actions."
Escalation Risks from Language Models in Military and Diplomatic Decision-Making
The various AI agents displayed "arms-race dynamics," leading to "greater conflict." As for which AI 'pushed the button,' that would be GPT-3.5 and Llama-2. The good news is that GPT 4 was more likely to de-escalate the situation and not turn the world into a nuclear wasteland.
"Based on the analysis presented in this paper, it is evident that the deployment of LLMs in military and foreign-policy decision-making is fraught with complexities and risks that are not yet fully understood," the paper concludes. "The unpredictable nature of escalation behavior exhibited by these models in simulated environments underscores the need for a very cautious approach to their integration into high-stakes military and foreign policy operations."

 Most people believe AIs like ChatGPT have some kind of 'consciousness' and 'feelings'
Most people believe AIs like ChatGPT have some kind of 'consciousness' and 'feelings' Newer AI models cheat to win at chess - maybe they're already more humanlike than we thought
Newer AI models cheat to win at chess - maybe they're already more humanlike than we thought Musk's Grok-3 is 'unhinged'... and that might bring back AI's lost creativity
Musk's Grok-3 is 'unhinged'... and that might bring back AI's lost creativity AI in real-life usage: Can't win an argument with your partner? Get ChatGPT to do it for you
AI in real-life usage: Can't win an argument with your partner? Get ChatGPT to do it for you Can you tell the difference between a real photo and an AI generated image?
Can you tell the difference between a real photo and an AI generated image? HDMI 2.2 products are coming in 2027 as chip makers begin sampling FRL2 silicon this year
HDMI 2.2 products are coming in 2027 as chip makers begin sampling FRL2 silicon this year Solo dev tries to make his own GTA 6 with AI, as he got tired of waiting for Rockstar
Solo dev tries to make his own GTA 6 with AI, as he got tired of waiting for Rockstar Repair channel buys ASUS RTX 4090 for $222 and finds plastic die with fake NVIDIA markings
Repair channel buys ASUS RTX 4090 for $222 and finds plastic die with fake NVIDIA markings Epic's gen AI use deters partners, Vampire Survivors x Fortnite might get cancelled
Epic's gen AI use deters partners, Vampire Survivors x Fortnite might get cancelled Sony seems to confirm singleplayer first-party PlayStation games will remain console exclusive
Sony seems to confirm singleplayer first-party PlayStation games will remain console exclusive NVIDIA GeForce GTX 1650 modded with 8GB of GDDR6 memory doubles performance in God of War and Unigine Superposition
NVIDIA GeForce GTX 1650 modded with 8GB of GDDR6 memory doubles performance in God of War and Unigine Superposition Apple will be working with Intel to design and build its chips in the USA, confirms President Donald Trump
Apple will be working with Intel to design and build its chips in the USA, confirms President Donald Trump GTA 6 pre-order date revealed by Rockstar
GTA 6 pre-order date revealed by Rockstar Anthropic's CEO confirms he can be fired as CEO through the company's own authority
Anthropic's CEO confirms he can be fired as CEO through the company's own authority Speed Racer (2008) 4K Ultra HD Blu-ray Review: a stunning remaster of the cult classic
Speed Racer (2008) 4K Ultra HD Blu-ray Review: a stunning remaster of the cult classic MOAIPLAY ORA PRO G1 850W ATX 3.1 PSU Review: high efficiency and 10-year warranty for $119.99
MOAIPLAY ORA PRO G1 850W ATX 3.1 PSU Review: high efficiency and 10-year warranty for $119.99 Navman MiVue Smart True 4K Surround Dashcam Review - Seeing In All Directions At Once
Navman MiVue Smart True 4K Surround Dashcam Review - Seeing In All Directions At Once IQUNIX Magi96 Pro Aluminum Low Profile Mechanical Keyboard Review - Premium Build, Satisfying Sound
IQUNIX Magi96 Pro Aluminum Low Profile Mechanical Keyboard Review - Premium Build, Satisfying Sound Asetek Forte S-Series Racing Simulator Bundle Review
Asetek Forte S-Series Racing Simulator Bundle Review Razer Pro Type Ergo Wireless Split Ergonomic Keyboard Review - Built for Comfort and Support
Razer Pro Type Ergo Wireless Split Ergonomic Keyboard Review - Built for Comfort and Support ASUS ROG Strix Morph 96 Wireless Gaming Keyboard Review - Great Performance, More Affordable
ASUS ROG Strix Morph 96 Wireless Gaming Keyboard Review - Great Performance, More Affordable SAPPHIRE Radeon RX 9070 GRE PULSE OC Review - A New 1440p Challenger Has Arrived
SAPPHIRE Radeon RX 9070 GRE PULSE OC Review - A New 1440p Challenger Has Arrived NZXT H6 RGB+ Compact Dual-Chamber Chassis Review
NZXT H6 RGB+ Compact Dual-Chamber Chassis Review ASRock Radeon RX 9070 GRE Steel Legend Review - The RDNA 4 Mid-Range Reshuffle
ASRock Radeon RX 9070 GRE Steel Legend Review - The RDNA 4 Mid-Range Reshuffle I read the Windows Backup app screen carefully, and it does not back up what most people think
I read the Windows Backup app screen carefully, and it does not back up what most people think Low Sound Volume on Windows 11? How to fix audio issues and restore normal volume
Low Sound Volume on Windows 11? How to fix audio issues and restore normal volume 8 Critical Warning Signs You Should Never Ignore in Windows 11
8 Critical Warning Signs You Should Never Ignore in Windows 11 This Windows security feature protects Documents from ransomware, but it is off by default
This Windows security feature protects Documents from ransomware, but it is off by default Windows 11 already has a voice typing tool, and it is the one most people are not using
Windows 11 already has a voice typing tool, and it is the one most people are not using Quick Assist is the only remote-support tool I open when a relative calls about their PC
Quick Assist is the only remote-support tool I open when a relative calls about their PC The PowerToys utilities I keep enabled on every Windows 11 PC, and the ones I turned off within a week
The PowerToys utilities I keep enabled on every Windows 11 PC, and the ones I turned off within a week TweakTown's Best of Computex 2026 Awards - The Best Hardware, Gaming Gear, and AI
TweakTown's Best of Computex 2026 Awards - The Best Hardware, Gaming Gear, and AI Phison E37T SSD Controller Exclusive Preview - The Fastest DRAMless SSD Platform Yet
Phison E37T SSD Controller Exclusive Preview - The Fastest DRAMless SSD Platform Yet