



Introduction
NVIDIA kind of blew us away with the reveal of the Pascal-based Tesla P100 at their own GPU Technology Conference back a few months ago, and now the company is back announcing that there are two new products for its Tesla P100 family of products.
The Tesla P100 is destined for HPC and datacenter applications, as they're designed to supercharge HPC applications by up to 30x compared to current-gen products. NVIDIA's new PCIe-based solutions are bound for datacenter and HPC markets once again, but the previous Tesla P100 products used a mezzanine connector, which required the utilization of the new servers - both cards are optimized to power the most computationally intensive AI and HPC datacenter applications.
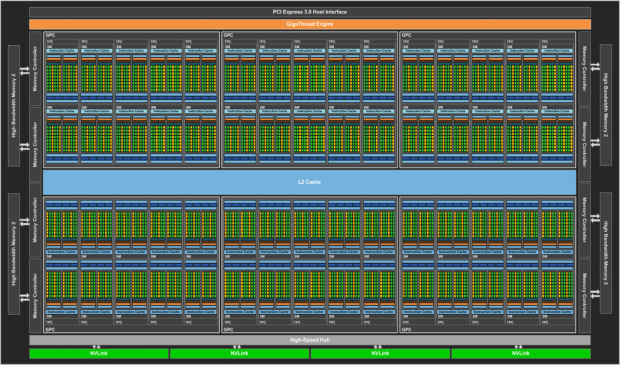
NVIDIA's new Tesla P100 variants come in 12GB and 16GB variants, with both framebuffers being powered by the next-gen HBM2 standard. Both cards feature the 16nm FinFET-based Pascal architecture, with 3584 CUDA cores, and redesigned SMs to support 64 CUDA cores per SM block. The Tesla P100 has 56 of these redesigned SMs, while the fully-enabled GP100 features 60 clocks in total. The Tesla P100 features a dedicated set of FP64 CUDA cores, while the 32 x FP64 cores per block, and the entire GPU features 1792 dedicated FP64 cores.
Pascal & HBM2 Still Perform Well With PCIe
Now that there's a PCIe-based variant that joined the NVLink-powered variant, we can look at the bandwidth between the two Tesla P100 products. NVLink is incredibly powerful, but it can't be used everywhere - so the Tesla P100 in for NVLink-enabled servers has up to 720GB/sec of memory bandwidth, while the PCIe-based Tesla P100 features 720GB/sec on the 16GB HBM2-based model, while the 12GB HBM2 model has 540GB/sec bandwidth.

The actual performance of the NVLink-based Tesla P100 versus the PCIe-based offering changes as well, with the NVLink-enabled Tesla P100 offering 5.3TFlops of double precision (DP) performance, while it has 10.6TFlops of SP performance, and a huge 21TFlops of half precision performance. Yeah, that's lots.
Comparing this to the PCIe-based Tesla P100, which has 4.7TFlops of DP, 9.3TFlops of single precision, and 18.7TFlops of half precision - the PCIe-based Tesla P100 isn't too bad at all. For more detail, the Tesla P100 PCIe-based card features:
- Unmatched application performance for mixed-HPC workloads - Delivering 4.7 teraflops and 9.3 teraflops of double-precision and single-precision peak performance, respectively, a single Pascal-based Tesla P100 node provides the equivalent performance of more than 32 commodity CPU-only servers.
- CoWoS with HBM2 for unprecedented efficiency - The Tesla P100 unifies processor and data into a single package to deliver unprecedented compute efficiency. An innovative approach to memory design - chip on wafer on substrate (CoWoS) with HBM2 - provides a 3x boost in memory bandwidth performance, or 720GB/sec, compared to the NVIDIA Maxwell™ architecture.
- PageMigration Engine for simplified parallel programming - Frees developers to focus on tuning for higher performance and less on managing data movement, and allows applications to scale beyond the GPU physical memory size with support for virtual memory paging. Unified memory technology dramatically improves productivity by enabling developers to see a single memory space for the entire node.
- Unmatched application support - With 410 GPU-accelerated applications, including nine of the top 10 HPC applications, the Tesla platform is the world's leading HPC computing platform.
Tesla P100 Is Powerful, Even on PCIe
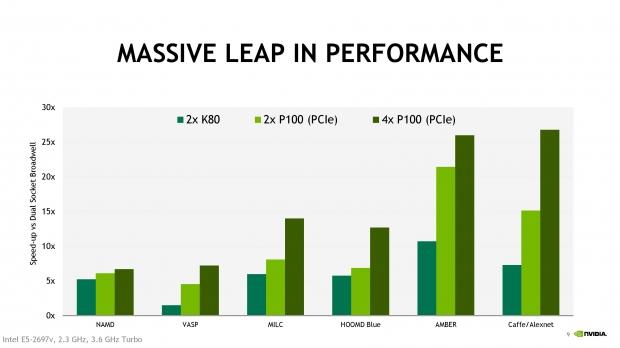
How's the performance? Well, you can see in the chart above that four of the PCIe-based Tesla P100 cards together, are pretty damn fast. It really does stomp all over the 2 x K80 cards in every test. Here's what we can expect from the PCIe-based Tesla P100:
Our Latest NVIDIA GeForce GPU Article Coverage
- ASUS ROG Strix GeForce RTX 5070 Ti 16GB OC Edition Review - Premium Design, Premium Performance
- COLORFUL iGame GeForce RTX 5070 Ultra OC Review - When Style and Performance Meet
- PNY GeForce RTX 5080 Slim OC Review - A Compact 4K Powerhouse
- MSI GeForce RTX 5060 Ti 16G VENTUS 2X OC PLUS Review
- MSI GeForce RTX 5070 Ti VENTUS 3X PZ OC Review - Hidden Cable, Visible Performance
- 4.7 teraflops double-precision performance, 9.3 teraflops single-precision performance and 18.7 teraflops half-precision performance with NVIDIA GPU BOOST™ technology
- Support for PCIe Gen 3 interconnect (32GB/sec bi-directional bandwidth)
- Enhanced programmability with Page Migration Engine and unified memory
- ECC protection for increased reliability
- Server-optimized for highest data center throughput and reliability
Available in two configurations:
- 16GB of CoWoS HBM2 stacked memory, delivering 720GB/sec of memory bandwidth
- 12GB of CoWoS HBM2 stacked memory, delivering 540GB/sec of memory bandwidth
- 16GB of CoWoS HBM2 stacked memory, delivering 720GB/sec of memory bandwidth
- 12GB of CoWoS HBM2 stacked memory, delivering 540GB/sec of memory bandwidth
Check Out These Benchmark Numbers
The NVLink-based Tesla P100 is already incredibly fast, and while the PCIe-based version isn't as fast, it still kicks some K80 ass.
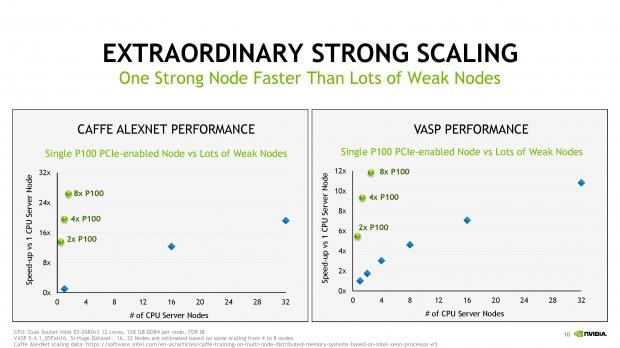
We can see extraordinarily strong scaling with Caffe AlexNet scaling data, where the speed-up vs. 1 CPU server node sees the PCIe-enabled NVIDIA Tesla P100 beating 'lots of weak nodes' as NVIDIA notes. The same is said of the VASP performance, with a single Tesla P100 thrashing out the larger number of weaker nodes.
NVIDIA Dominates Deep Learning
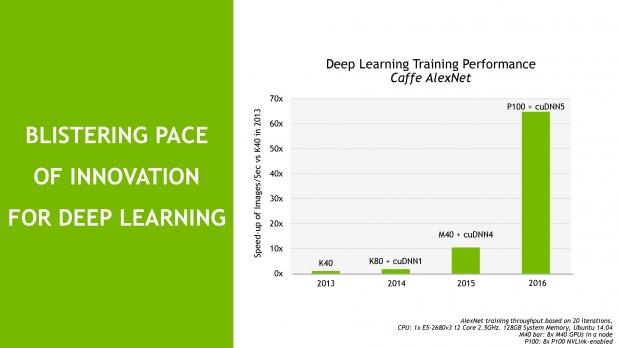
NVIDIA has a significant investment into Deep Learning, with the original NVLink-based Tesla P100 video card put into 'deep learning training performance' on Caffe AlexNet, where it completely crushes the K40 released in 2013, and even the newer K80 and M40 offerings - where we get a better idea of how fast the Pascal architecture is mixed on the 16nm FinFET process with HBM2 technology.

Deep Learning continues to evolve, with NVIDIA's software including objection detection, and more.
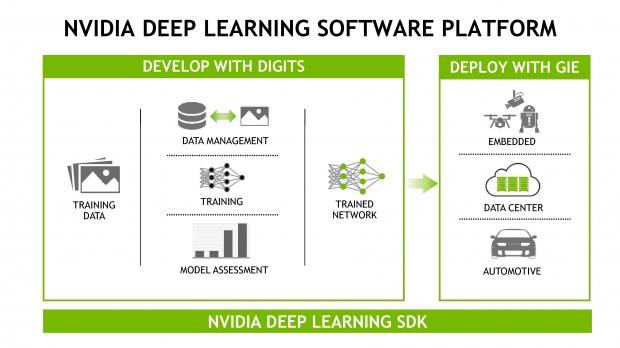
NVIDIA has a comprehensive Deep Learning software platform, where you can develop with different software, and through to their Deep Learning SDK.
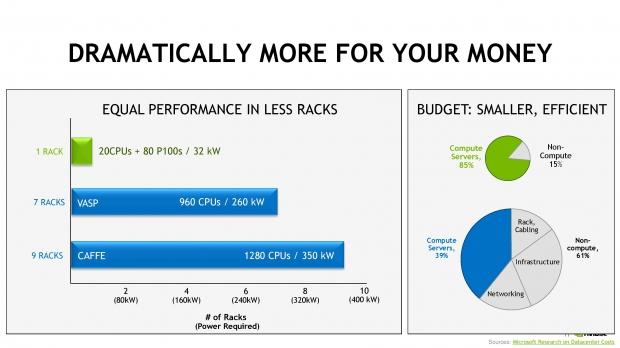
NVIDIA's new Tesla P100 cards will also save you money, as a single-rack, 20-processor system with 80 x Tesla P100s uses 32kW of power - quite a lot, right? Well, it pales in comparison to a VASP 7-rack, 960-processor system (960 processors versus 20 processors) and it uses 260kW - this is how much more efficient the Pascal-based Tesla P100s can make datacenters. If we compare it to Caffe 9-rack system with a 1280-processor system which uses 350kW.
The Future of GeForce is Pascal + 16nm + HBM2
While NVIDIA's new Tesla P100 might not seem exciting because it's not a GeForce card, it shows the strides the company is making in the professional video card market, and especially Deep Learning. NVIDIA's research into Deep Learning is expansive, and they have a near dominance in the market with AMD not pushing much into the area.
NVIDIA makes a considerable chunk of money from the professional market, with multiple supercomputers being powered by NVIDIA products, as well as datacenters, visual FX studios, and more. NVIDIA is taking market share away from the likes of Intel, as the dependence on high-end CPUs which need to be clustered together in a 7- or 9-rack system using 10x the power to compete with a single Tesla P100-powered rack.
The new Pascal architecture mixed with 16nm FinFET process makes a lot of this possible, with NVIDIA riding the Holy Trinity of technology for the Tesla P100 - Pascal, 16nm FinFET process, and HBM2 technology. HBM2 provides up to 1024GB/sec and with the new 12/16GB variants pushing out this type of power, we can expect the consumer GeForce cards based on a full-fat GP100 GPU and HBM2 should arrive in 12/16GB models, with some serious speed bumps.
The GP100 should power the GeForce GTX 1080 Ti, where I think it'll be powered by GDDR5X memory, while a second card could arrive with a more premium pricing, but powered by HBM2. If NVIDIA splits the new GeForce card into two; one with GDDR5X and one with HBM2, we can expect a rather large leap in performance over the already dominant GTX 1080.
HBM2 yields aren't that high right now, and won't improve more until early 2017, which is another issue. NVIDIA will most likely use GDDR5X on the GeForce GTX 1080 Ti while the Titan X successor will use HBM2 and arrive in a 12/16GB model. The original GeForce GTX Titan X had 12GB of GDDR5, the most amount of VRAM on a consumer card ever. 12/16GB models of the GP100-based GeForce card make sense, but HBM2 is rather expensive - meaning the Titan X successor will likely be priced way above the original $999 pricing on Titan X.
Speculating further, the GeForce GTX 1080 Ti could be priced at $999 (up from the $699 on the GeForce GTX 1080 Founders Edition), while the purported Titan X successor with a speculated 12GB of HBM2, could be priced at $1499, while the 16GB model bumped up to somewhere around $1999. But again, this is complete speculation, based on the price of the GTX 1080 cards right now.
The next 12 months will be beyond exciting because we should see the tease of Volta in 2017, NVIDIA's next-gen architecture that will succeed Pascal. Volta is said to deliver an incredible leap in performance over Pascal, something I'm excited to see.
 SAPPHIRE Radeon RX 9070 GRE PULSE OC Review - A New 1440p Challenger Has Arrived
SAPPHIRE Radeon RX 9070 GRE PULSE OC Review - A New 1440p Challenger Has Arrived ASRock Radeon RX 9070 GRE Steel Legend Review - The RDNA 4 Mid-Range Reshuffle
ASRock Radeon RX 9070 GRE Steel Legend Review - The RDNA 4 Mid-Range Reshuffle ASUS ROG Strix GeForce RTX 5070 Ti 16GB OC Edition Review - Premium Design, Premium Performance
ASUS ROG Strix GeForce RTX 5070 Ti 16GB OC Edition Review - Premium Design, Premium Performance SAPPHIRE Radeon RX 9070 XT NITRO+ PhantomLink Review - RDNA 4's Beast Mode
SAPPHIRE Radeon RX 9070 XT NITRO+ PhantomLink Review - RDNA 4's Beast Mode COLORFUL iGame GeForce RTX 5070 Ultra OC Review - When Style and Performance Meet
COLORFUL iGame GeForce RTX 5070 Ultra OC Review - When Style and Performance Meet Rampant fraud forces Valve to cut Steam gift card sales
Rampant fraud forces Valve to cut Steam gift card sales Microsoft sets a Patch Tuesday record with 206 fixes, and finally patches every zero-day Nightmare Eclipse disclosed
Microsoft sets a Patch Tuesday record with 206 fixes, and finally patches every zero-day Nightmare Eclipse disclosed Todd Howard is playing Elder Scrolls VI and it looks 'amazing,' Xbox exec says
Todd Howard is playing Elder Scrolls VI and it looks 'amazing,' Xbox exec says Google orders Intel Foundry to produce over three million TPUs for 2028 amid TSMC capacity crunch
Google orders Intel Foundry to produce over three million TPUs for 2028 amid TSMC capacity crunch Half-Life now runs on a 2007 Nokia N95 at 30 FPS with Bluetooth mouse support
Half-Life now runs on a 2007 Nokia N95 at 30 FPS with Bluetooth mouse support GIGABYTE's hidden Z990 motherboard at Computex reveals six NVMe slots and three PCIe 5.0 M.2 bays for Nova Lake-S
GIGABYTE's hidden Z990 motherboard at Computex reveals six NVMe slots and three PCIe 5.0 M.2 bays for Nova Lake-S Xbox to hold major layoffs as profit margins drop to 3%
Xbox to hold major layoffs as profit margins drop to 3% Xbox clarifies what 'console exclusive' actually means
Xbox clarifies what 'console exclusive' actually means Anthropic's latest AI model Claude Fable just built Minecraft for less than $50
Anthropic's latest AI model Claude Fable just built Minecraft for less than $50 Microsoft legal is evaluating Anthropic's Claude Fable over how it saves prompts and output
Microsoft legal is evaluating Anthropic's Claude Fable over how it saves prompts and output MOAIPLAY ORA PRO G1 850W ATX 3.1 PSU Review: high efficiency and 10-year warranty for $119.99
MOAIPLAY ORA PRO G1 850W ATX 3.1 PSU Review: high efficiency and 10-year warranty for $119.99 Navman MiVue Smart True 4K Surround Dashcam Review - Seeing In All Directions At Once
Navman MiVue Smart True 4K Surround Dashcam Review - Seeing In All Directions At Once IQUNIX Magi96 Pro Aluminum Low Profile Mechanical Keyboard Review - Premium Build, Satisfying Sound
IQUNIX Magi96 Pro Aluminum Low Profile Mechanical Keyboard Review - Premium Build, Satisfying Sound Asetek Forte S-Series Racing Simulator Bundle Review
Asetek Forte S-Series Racing Simulator Bundle Review Razer Pro Type Ergo Wireless Split Ergonomic Keyboard Review - Built for Comfort and Support
Razer Pro Type Ergo Wireless Split Ergonomic Keyboard Review - Built for Comfort and Support ASUS ROG Strix Morph 96 Wireless Gaming Keyboard Review - Great Performance, More Affordable
ASUS ROG Strix Morph 96 Wireless Gaming Keyboard Review - Great Performance, More Affordable NZXT H6 RGB+ Compact Dual-Chamber Chassis Review
NZXT H6 RGB+ Compact Dual-Chamber Chassis Review ASRock Z890 Taichi Aqua Motherboard Review - Flagship features without the flagship price
ASRock Z890 Taichi Aqua Motherboard Review - Flagship features without the flagship price The PowerToys utilities I keep enabled on every Windows 11 PC, and the ones I turned off within a week
The PowerToys utilities I keep enabled on every Windows 11 PC, and the ones I turned off within a week TweakTown's Best of Computex 2026 Awards - The Best Hardware, Gaming Gear, and AI
TweakTown's Best of Computex 2026 Awards - The Best Hardware, Gaming Gear, and AI Phison E37T SSD Controller Exclusive Preview - The Fastest DRAMless SSD Platform Yet
Phison E37T SSD Controller Exclusive Preview - The Fastest DRAMless SSD Platform Yet USB Ports Not Working in Windows 11? Try These Fixes
USB Ports Not Working in Windows 11? Try These Fixes ASUS WiFi Routers and Networking Solutions Deliver Long-term Security and Reliability with No Additional Cost
ASUS WiFi Routers and Networking Solutions Deliver Long-term Security and Reliability with No Additional Cost Second Monitor Not Detected in Windows 11? Try These Fixes
Second Monitor Not Detected in Windows 11? Try These Fixes Turn Your Old Smartphone Into a Dedicated Webcam for Your Windows PC
Turn Your Old Smartphone Into a Dedicated Webcam for Your Windows PC The Send To menu is the right-click feature on Windows 11 that nobody bothers to customize
The Send To menu is the right-click feature on Windows 11 that nobody bothers to customize Windows 11 will not let you pin a folder to the taskbar, but a 30-second workaround does
Windows 11 will not let you pin a folder to the taskbar, but a 30-second workaround does ASUS ProArt Displays Unlock Creativity with Professional Monitors for Everyone
ASUS ProArt Displays Unlock Creativity with Professional Monitors for Everyone